

Failover vs. Failback: What’s the Difference?
Pure Storage
MAY 16, 2024
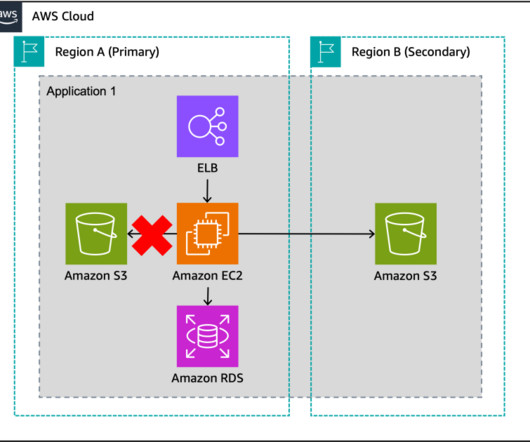
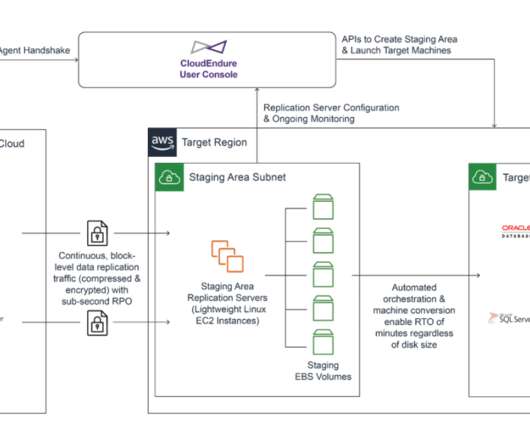
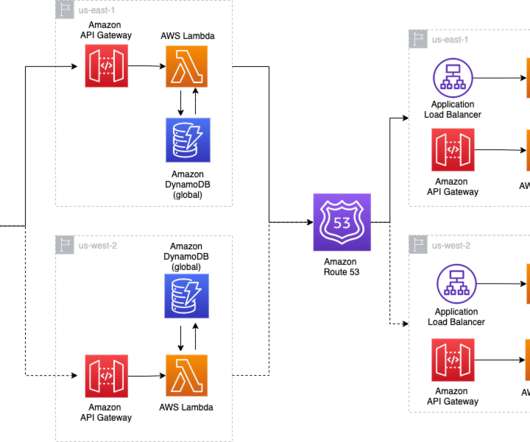
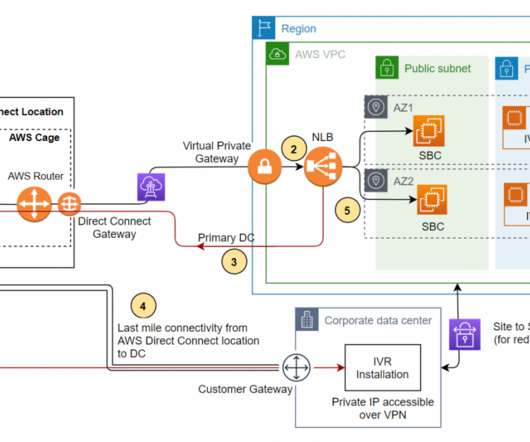
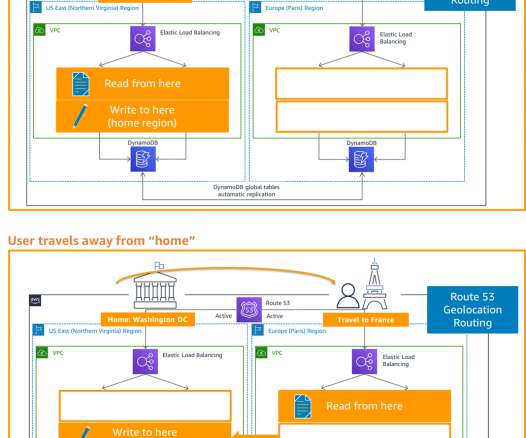
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? Their effects, however, couldn’t be more different.







































Let's personalize your content