

Two Outages in Two Weeks? Get DR for AWS
Zerto
DECEMBER 21, 2021
Give your organization the gift of Zerto In-Cloud DR before the next outage . But I am not clairvoyant, and even I could not have predicted two AWS outages in the time since then. On December 7, 2021, a major outage in the form of a DNS disruption in the North Virginia AWS region disrupted many online services.
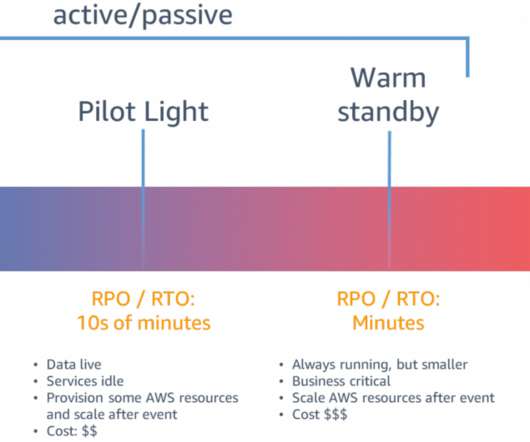

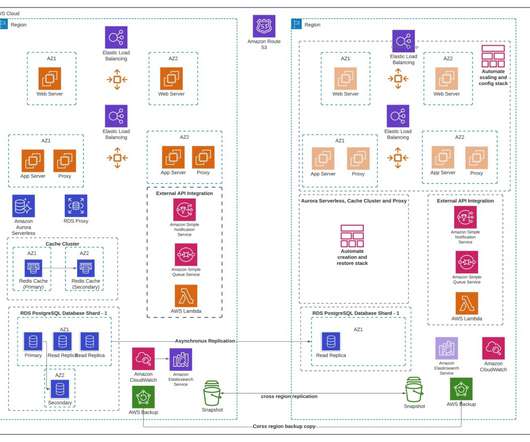

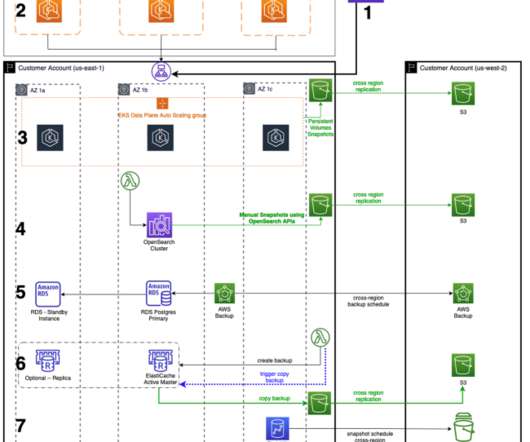

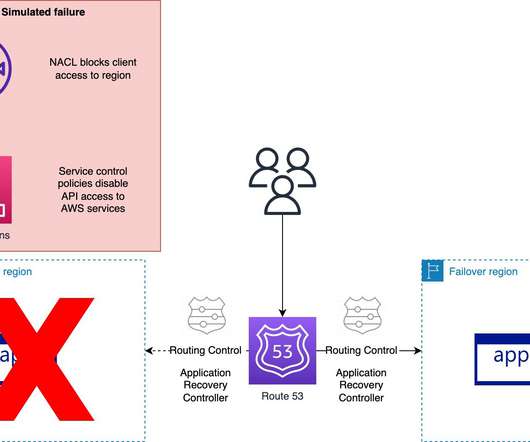












Let's personalize your content