

Unlocking the Secrets of Uninterrupted IT Operations: Demystifying High Availability and Disaster Recovery
Zerto
SEPTEMBER 12, 2023
In the challenging landscape of keeping your IT operations online all the time, understanding the contrasting methodologies of high availability (HA) and disaster recovery (DR) is paramount. Here, we delve into HA and DR, the dynamic duo of application resilience. What Is High Availability?





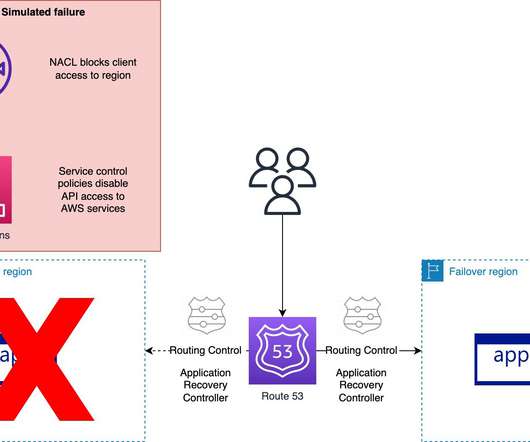

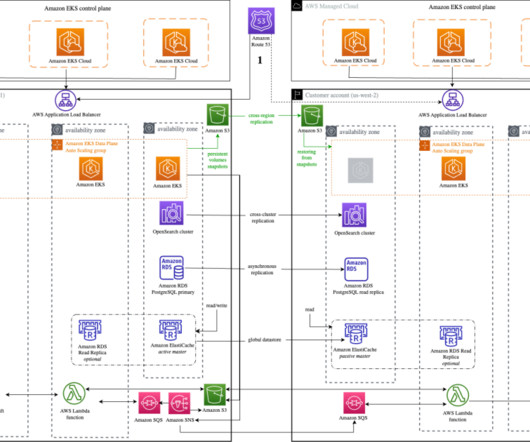
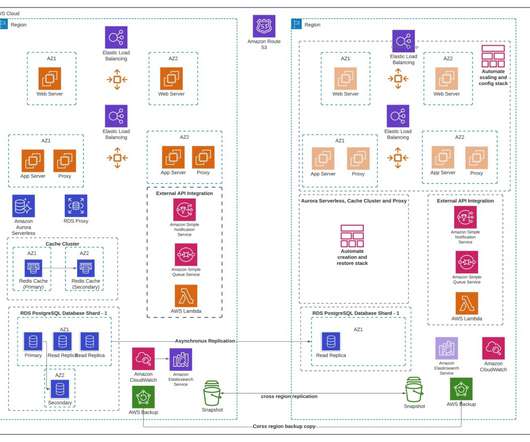







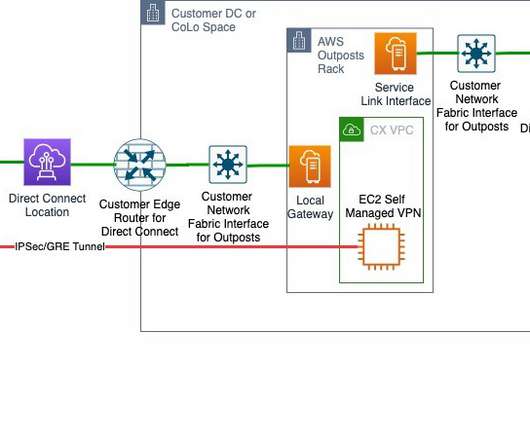


Let's personalize your content