
Disaster Recovery (DR) Architecture on AWS, Part IV: Multi-site Active/Active
AWS Disaster Recovery
JUNE 23, 2021
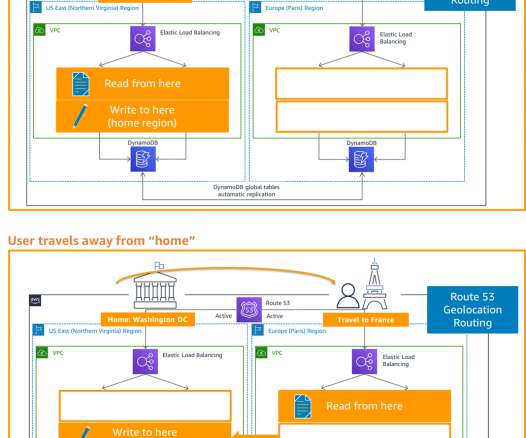
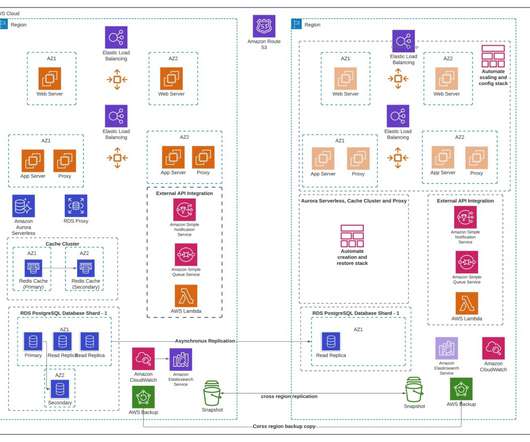
Each Region hosts a highly available, multi- Availability Zone (AZ) workload stack. Figure 2 shows Amazon Route 53 , a highly available and scalable cloud Domain Name System (DNS) , used for routing. Alternatively, you can use AWS Global Accelerator for routing and failover. Each regional stack serves production traffic.


Let's personalize your content