

Comparing Resilience: Business, Operational, IT, and Cyber – Part Three
Zerto
OCTOBER 6, 2022
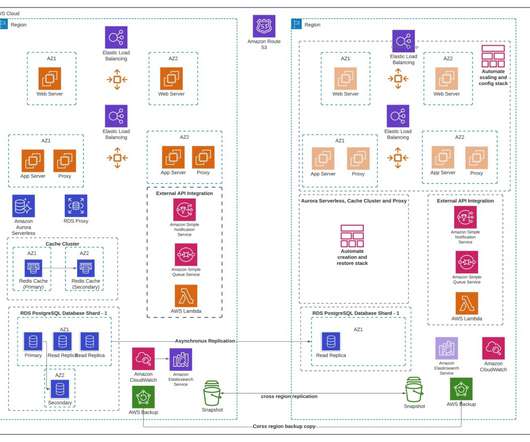
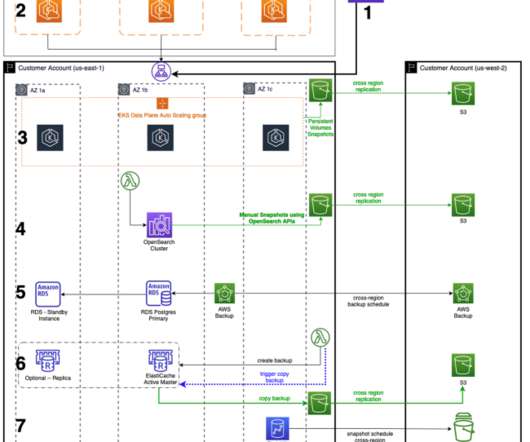
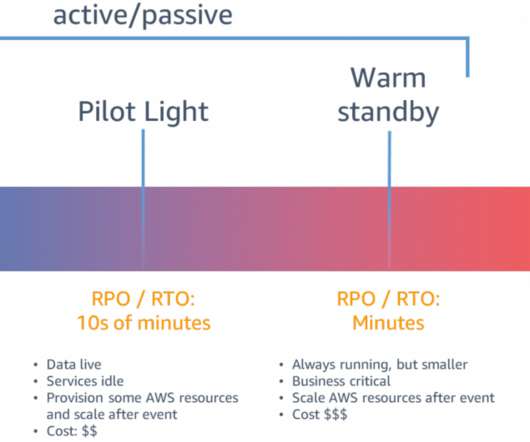
In part one , we covered business resilience. In part two , we went over operational resilience and showed its slightly narrower scope and approach. In part three, we are going to look at a cornerstone of business resilience, IT resilience. What Is IT Resilience? How Do You Ensure IT Resilience?







Let's personalize your content