
Implementing Multi-Region Disaster Recovery Using Event-Driven Architecture
AWS Disaster Recovery
JULY 27, 2021
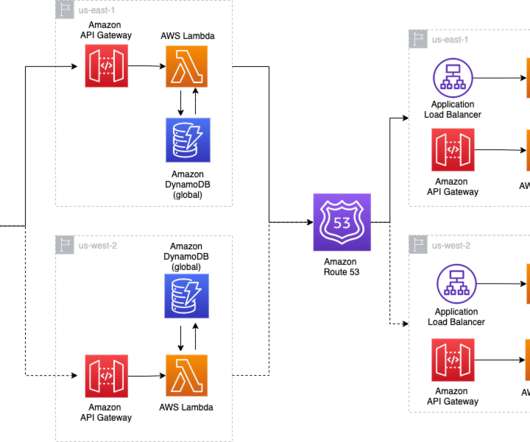
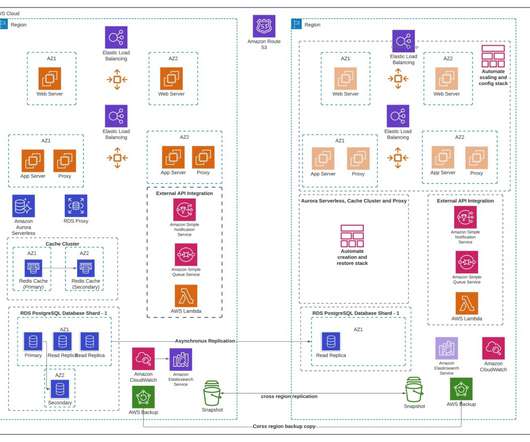
We highlight the benefits of performing DR failover using event-driven, serverless architecture, which provides high reliability, one of the pillars of AWS Well Architected Framework. With the multi-Region active/passive strategy, your workloads operate in primary and secondary Regions with full capacity. Amazon RDS database.




Let's personalize your content