
Disaster Recovery (DR) for a Third-party Interactive Voice Response on AWS
AWS Disaster Recovery
SEPTEMBER 16, 2021
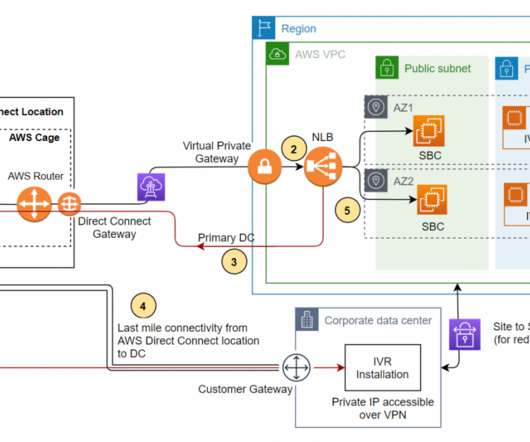
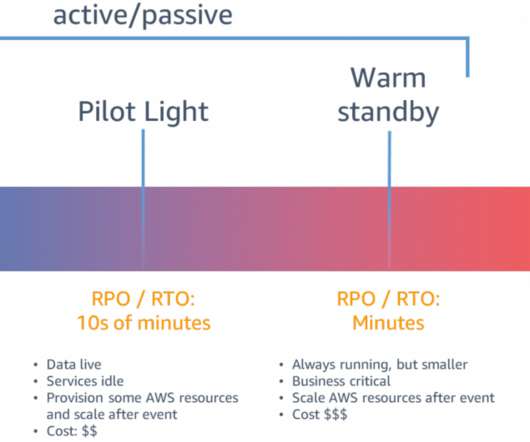
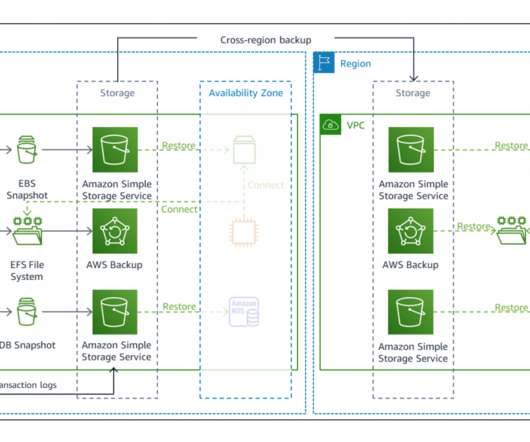
The workload has a recovery time objective (RTO) and a recovery point objective (RPO). RPO is the maximum acceptable amount of time since the last data recovery point. This architecture enables customers facing challenges of cost overhead with redundant Session Initiation Protocol (SIP) trunks for the DC and DR sites.








Let's personalize your content