

Design an Azure Data Platform that InfoSec will love – Azure Databricks
In the first post of this series, I set out the foundation of our secure Data Lakehouse. It makes sense to continue with the heart of the platform; the compute engine Azure Databricks.
Azure Databricks
Azure Databricks is an analytics platform and often serves as the central compute component of a data platform, to process ETL/ELT data pipelines and data science workloads. As Databricks is a third-party platform-as-a-service offering securing it works differently to most other first-party services in Azure; for example, we can’t use private endpoints. (More on these in the Azure Storage post)
The two main approaches to working with Databricks in our secure platform are VNet Peering or VNet Injection
VNet Peering vs VNet Injection
So what’s the difference between these two approaches? In short, do we want our Databricks workspace and cluster resources inside our own VNet (injection) or do we want to peer our VNet with a Databricks managed VNet (peering).
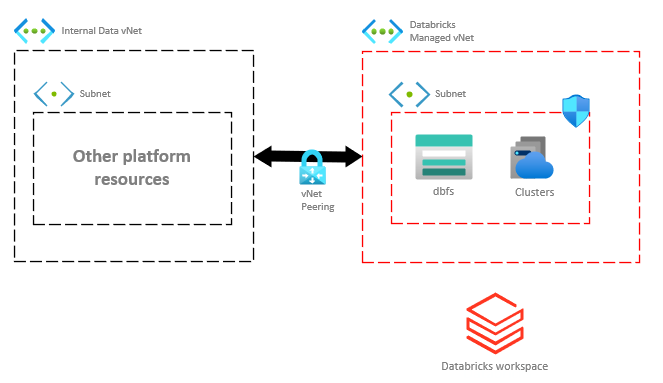
Databricks VNet Peering
An important distinction here is that the Databricks workspace essentially sits in the public cloud when using VNet peering.
I’d recommend going with VNet injection as, although painful, it’s a more common route and having everything inside your own VNet offers greater security.
With VNet Injection, the Databricks workspace and cluster resources sit inside our VNet in their own subnets, which are referred to as public and private subnets in the documentation (just to trigger Security). In reality, if you’ve turned off the Public IP, nothing about it is public. For this reason, it’s best to stick to their alternate, Host and Container naming convention.
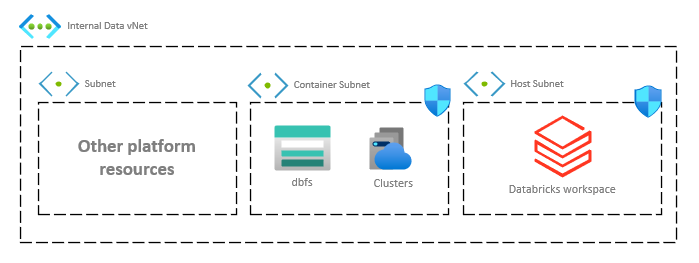
Databricks VNet Injection
Before you create anything!
Check out Microsoft’s docs on Deploying Azure Databricks in your Azure virtual network as they cover the requirements and considerations in much greater detail. To summarise, here’s a few important points to remember before getting started:
Ensure your Container (“private”) subnet contains enough addresses for the clusters you intend to use. Future proof this as much as you can as it is a full tear down to fix if you need to do it later!
You can’t switch an existing Databricks workspace over to use VNet injection. This has to be configured from creation.
Disable the public IP address by enabling Secure Cluster Connectivity. (This is a poorly worded feature in my opinion)
Azure Policies on managed resources
As I mentioned earlier, the cluster resources will be provisioned within the container (private) subnet but they will be created inside their own managed resource group, NOT the resource group you deploy the Databricks workspace (and all other resources to).
This is standard for Databricks regardless of how its deployed but with more secure implementations, Security and Administration teams tend to go wild with Azure Policies to enforce and restrict features, and naming conventions. Managed resources need to be put on an exemption list.
Traffic routing
With vNet injection we have a fully secure Databricks environment which is great but it also means that all of that connectivity to public resources that is taken for granted is now restricted and may need Firewall exceptions raised.
As detailed in the Databricks data exfiltration protection post, we need to add a route table to ensure we correctly route traffic through the firewall. This is essential to allow clusters to come online as they reach out to other azure resources on the public cloud.
Microsoft’s documentation has full details on the user-defined route settings for each region.
Role-Based Access Control (RBAC)
This is where we want to consider the services and tools that are likely to interact with Databricks. Some of these points will be optional if you haven’t opted to use them in your data platform
Data Factory
The most secure connectivity method between Data Factory and Databricks is to utilise Data Factory’s managed identity. This avoids the use of Databricks Personal Access Tokens (PAT) which are connected to a specific user and act as a password.
Your Data Factory instance needs to be added as a Contributor on the Databricks workspace and there’s a brief how-to for this on Microsoft’s tech community blog.
NOTE: These permissions are quite high and if this is likely to cause concern you can set them in a more granular way using the Azure CLI
Key Vault
Once we have our Key Vault deployed and set up to use RBAC instead of ACLs, we need to add the AzureDatabricks App as a Key Vault Secrets User too. This gives Databricks the ability to access secrets in our Key Vault.
There are other Key Vault permissions we will need to set to use features such as Customer managed keys but these will be covered later in the series.
Cluster Security
The focus of this post has been securing Databricks from the outside, concentrating on network configuration and security features but it’s important to remember the internal security. Restricting who has access to provision new clusters is just as important when considering that standard clusters using AAD pass-through can be used to impersonate another user when connecting to a storage mount.
With Databricks permissions, as with the RBAC roles above, it’s important to know what personas people fit into to ensure the access granted is appropriate for their role and responsibilities. I have previously covered how to define basic Data Personas on my personal blog site.