

Unleashing the Power of OCR: How to Extract Value from Unstructured Data

Exploding Data: The Unprecedented Growth of Data
We all know that data is exploding in an unprecedented way. By 2025, the IDC predicts the global data volume will grow from 33 zettabytes in 2018 to 175 zettabytes (a zettabyte is a trillion gigabytes).
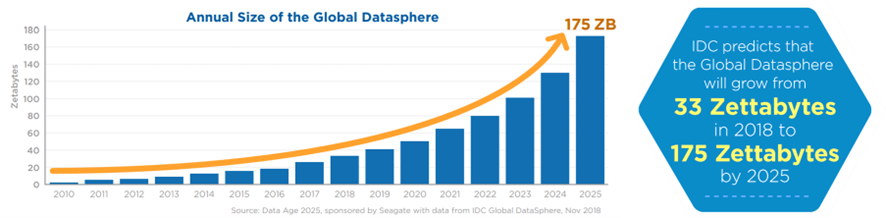
How big is 175ZB?
According to IDC’s ‘Data Age 2025’ paper:
If you were to store 175 zettabytes on DVDs, your stack of DVDs would be long enough to circle Earth 222 times.
If you attempted to download 175 zettabytes at the average current internet connection speed, it would take you 1.8 billion years to download. Even if you enlisted every person in the world to help with the download, it would still take 81 days.
That's a huge amount of data, and it's only going to continue to grow. But did you know that 80% to 90% of this data is unstructured and is growing at 55% -65% each year?
Unstructured data is difficult to analyse and therefore, difficult to make decisions from. As a result, many business leaders struggle to harness the value within unstructured data for better decision-making and improved productivity. This unstructured data is often referred to as "dark data" as it is not in a structured, machine-readable format and therefore not used for other purposes.
In this article, we will explore what structured and unstructured data mean and see how we can tap into the potential value that unstructured data can hold. Sometimes, it can be difficult to make sense of unstructured data, but there are tools out there that can help us extract useful information from it. For example, there are tools that can take images and turn them into text that we can then analyse. There are even free, open-source options out there that we can use to get the job done.
So let's get started!
What is structured data? How is it different to unstructured data?
Structured vs Unstructured
Structured data is typically categorised as quantitative data, is highly organised, labelled, and machine-readable, allowing it to be automatically processed, accessible and comprehensible. Microsoft Office Excel files are an example of structured data where the data typically has both text and numbers and is stored in a structured manner, i.e., in a column-row format.

Unstructured data however is the opposite, it can’t be easily stored in a traditional column-row database or spreadsheet, making it more difficult to access, process and analyse. Some examples of unstructured data are:
Scanned documents of invoices, receipts, medical forms, books etc,
Doctor’s notes
Images
Audio and video files
Call centre transcripts or recordings
Social media profiles and posts

How can we extract value from unstructured data?
One way to extract value from unstructured data is through the use of Optical Character Recognition (OCR). OCR is a form of computer vision that is used to extract text from images and convert it into a structured format. This technology has been around for a long time but is becoming increasingly more popular due to the growing amount of unstructured data.
Just like how Scrabble tiles can be rearranged to form valuable words, OCR allows businesses to extract value from unstructured data by converting it into a structured format. Using OCR, organisations can effectively classify, categorize, and analyse unstructured documents and images, extracting valuable insights that can help them make better informed decisions.
What can we do after extracting text from unstructured data?
Once you have extracted structured data from unstructured documents and images, there are many ways you can leverage this data to drive value in different industries. Here are a few examples:
Healthcare: In the healthcare industry, OCR can be used to digitise and organise large volumes of medical records and patient information, enabling faster and more efficient access to critical data.
Finance and banking: OCR can help financial institutions automate the process of extracting data from scanned documents, such as invoices, receipts, and bank statements. This can save time and reduce the risk of errors.
Legal: OCR can assist legal firms in converting scanned documents, such as contracts and legal briefs, into searchable and editable text files. This can improve the efficiency of legal research and document management.
Retail: OCR can be used to extract data from receipts and invoices, enabling retailers to automate their accounts payable processes and gain better visibility into their financial data.
Government: OCR can help government agencies automate the process of extracting data from forms, such as tax returns and applications for benefits. This can reduce the workload of government employees and improve the accuracy of data collection.
Manufacturing: OCR can be used to extract data from production and quality control documents, such as inspection reports and test results. This can help manufacturers to track and analyse performance, identify problems, and improve quality.
Education: OCR can assist educators in digitising and organising large collections of scanned documents, such as textbooks and study guides. This can make it easier for students to access and search for information.
These are just a few examples of how OCR can be used to extract value from unstructured data in different industries. The possibilities are endless and in short, OCR can be used to improve data management, increase productivity and make more informed decisions.
How can we leverage OCR to extract text from images?
There are many tools available to enable the extraction of text from unstructured data, both free and paid. Some free popular options include Tesseract, EasyOCR and Keras-OCR. There are also paid, cloud-based options such as Azure Form Recognizer, Amazon Textract and Google cloud vision.
In this article, we'll check out Pytesseract - an open-source Python library that works with Google's Tesseract-OCR Engine (which is one of the most accurate OCR engines out there).
Example
Let’s look at one of the use cases described above:
Finance and banking: OCR can help financial institutions automate the process of extracting data from scanned documents, such as invoices, receipts, and bank statements. This can save time and reduce the risk of errors.
As a financial institution, it is important to be able to understand and process invoices efficiently. In this example, we will examine an invoice in French created by Contoso, a fictional company used by Microsoft. We will digitise the invoice using OCR, which then allows us to easily analyse the content.
Using Pytesseract
We now read in the invoice that is stored as a png file and display it.
This is the image we're working with. It's an invoice for some products. If you only have one invoice, it's easy to extract information, but when you have hundreds or thousands of invoices, it becomes a very difficult task. This is where we will leverage pytesseract to help us extract information easily.

All we do now is use Pytesseract to useful information regarding the detected words. We can do this by using the following line of code:
This code block will print the values in the dictionary called results, which include left, top, width, height, text, and conf.

Among the data returned by pytesseract.image_to_data():
The term
textrefers to the words detected.Leftis the distance from the upper-left corner of the bounding box to the left border of the image.Topis the distance from the upper-left corner of the bounding box to the top border of the image.WidthandHeightare the dimensions of the bounding box.Confis the model's confidence in its prediction for the word within the bounding box. IfConfis -1, it indicates that the bounding box contains a block of text rather than a single word.
Now we can draw boxes around the detected texts and visualise how good the text extraction is.
And that’s it! As simple as that, we can see the texts that are extracted from the image.

To store the text, then the following line of code will convert the detected text into a string:

After completing the digitisation process, or extracting the text from the image, there are many options for what to do next. As an example, we can translate the extracted text from French to English to understand the contents of the invoice.
By extracting text from this image, we can now see exactly what was invoiced - lawn, concrete, and mulch. This is really helpful!
Wrapping Up
In summary, OCR can help businesses make sense of unstructured data by turning it into structured data. This is especially useful in industries like healthcare, finance, legal, retail, and government where there's a lot of paper documents and images that need to be digitised and organised. As the amount of unstructured data grows, OCR is definitely a valuable tool for improving decision-making and productivity.
If you are intending to do this at scale and with the added benefits of the cloud, then it’s worth looking at services like Form Recognizer. Form Recognizer is a cloud-based service provided by Microsoft Azure that uses advanced machine learning to extract text, key-value pairs, tables, and structures from documents automatically and accurately.