

Microsoft Fabric: An introduction to OneLake
As data engineers, we face many challenges daily. Data is often distributed across many different sources, and frequently in a wide range of file types with varying levels of data quality. So much time is spent finding where a certain file resides; which tenant? What are the access rights? Thus reducing the amount of time spent on what actually matters. This is where OneLake comes in.
“OneLake is the OneDrive for data and like OneDrive, OneLake is provisioned automatically with every Fabric tenant with no infrastructure to manage.” -Microsoft
Benefits include:
Unified data storage across domains and tenants
Managed and unmanaged data storage
Full Delta support using VertiParq
Distributed ownership of data and security
DirectLake (powerful PowerBI support)
OneLake: What is it?
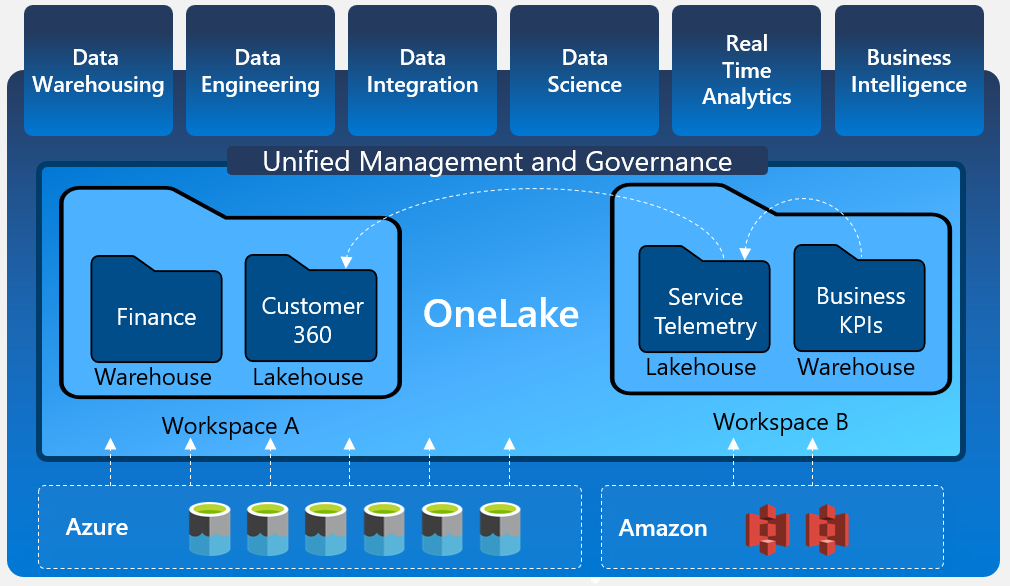
OneLake architecture showcasing the ability to connect to multiple cloud providers
Above we see the basic concept of OneLake and some of the benefits it provides. There are two symbolic links (Shortcuts) to both Azure and Amazon storage. Data from these can be seen inside of respective workspaces within the same OneLake. This offers unified management and governance of the data. Then all the personas from data engineers, to real time analysts, to BI developers sitting on top of the OneLake can access the data directly.
Data stored within the OneLake supports the open source delta file format, and is the default for the managed area of the lake. Here at AA we are big fans of the delta file format. You may already be familiar with this file type, but in case you aren’t, it offers optimised storage for data engineering workflows, featuring efficient storage, versioning, schema enforcement, ACID transactions, and streaming support. It also integrates well with Apache Spark, making it ideal for large-scale data processing applications.
There are many ways to get your data into the OneLake. I’ve found the easiest way is through Shortcuts. Shortcuts are a way of creating a symbolic link to external storage locations. Shortcuts can also be used to simplify file paths, making it easier for users to navigate complex directory structures. The second ingestion method I’ve been using is data pipelines, which if you’ve worked with Data Factory or Synapse before, should feel extremely familiar. Both approaches can be used to link external lakes into the Managed Tables area - if the data is stored in delta - or in the unmanaged form via the Files section if using other file formats. For this blog I’m going to assume you have data stored within the OneLake.
Your Managed Data: Tables
In the lakehouse architecture, tables play a crucial role in managing and organizing data. Once you have set up your tables in the managed section of the lakehouse, you have several options for browsing, querying, and analysing your data.
Browsing tables with the Lakehouse Explorer
One of the key benefits of having tables in the managed section, is that you can easily browse them via the lakehouse explorer. This feature is particularly useful for checking the schema is correct, as well as quickly being able to view a sample of the data. There are also more advanced uses, like checking the delta logs to ensure that the tables have been set up correctly, as well as comparing compression and optimisation for managed tables.
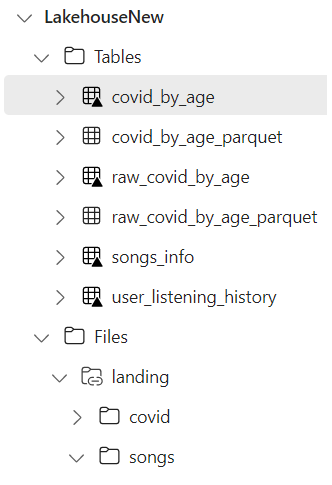
Lakehouse UI menu within Microsoft Fabric, showing the Tables and Files sections
Accessing tables for SQL queries or dataframes
Once your data is inside the managed section, you have access to the namespace LakehouseName.TableName. This means that you can use SQL queries on your data, or read the data into a dataframe using spark.sql (and any other supported language). This gives you the flexibility to manipulate and analyse your data in a way that suits your needs and utilises the skills of your team.
Relative and absolute path
In addition to the namespace, you also have access to the relative and absolute path of your managed tables. For example, if you have a table named "std_songs_history", the relative path would be "/Tables/std_songs_history". This makes it easy to reference your tables when working inside of the notebook editor or even with other tools. Or when using externally the full path would be used i.e. abfss://xxxx@onelake.dfs.fabric.microsoft.com/yyyyyyy-zzzz/Tables/std_songs_history.
Familiarity
Once your data is in the managed section and you have set up your tables, working with it is no different from any other tool such as Databricks or Synapse. You can use the same familiar commands, code, and tools to analyse and manipulate your data, giving you the flexibility and control, you need to get the most out of your lakehouse architecture, whilst minimising learning overhead.
Tables in the managed section of a lakehouse architecture give you powerful tools for managing and analysing your data. Whether you are working with SQL queries or dataframes, the flexibility and control offered by tables make them an essential part of any successful lakehouse architecture and a key area of the OneLake.
Your Unmanaged Data: Files
In a lakehouse architecture, not all data needs to be managed. In fact, there are many cases where data is better left in its raw form, outside of the managed tables. For these cases, the OneLake lakehouse architecture provides the ‘Files’ section, where you can store and access any file format.
Linking to multiple data sources
One of the key benefits of using the Files section is the ability to link to multiple data sources in either the same tenant or an external tenants. This means that you can easily access data from external sources and use it in your analysis without having to manage data transportation or authentication (this is done when creating the link to the external source). This is particularly useful when working with third-party data lakes or databases.
Referencing files by path
Unlike the managed area of the lakehouse, datasets stored within the Files section are outside of the database namespace and must be referenced by file paths. Although the data found here will often reside in external and potentially third-party data lakes/databases, the relative path will always be “Files/...” and the absolute path will be a “onelake.dfs.fabric URL”. This gives you the flexibility to reference any file format from any data source, making it easy to work with even the most complex datasets.
Storing and accessing any file format
The Files section of the lakehouse architecture is designed to store and access any file format. This means that you can work with a wide range of data types, including CSV, JSON, Parquet, Avro, as well as unstructured data formats. This gives you the flexibility to work with the data in its raw form, without having to convert it to a specific format first. This opens the door to data engineers, data scientists and data analysts to dive further into the data and potentially find more insights for their businesses.
The Files section of the lakehouse architecture gives you powerful tools for working with unmanaged data. Whether you are linking to multiple data sources, referencing files by path, or working with any file format, the flexibility and control offered by the Files section make it an essential area of the OneLake and will lead to a successful lakehouse implementation.
Other Benefits
A small but notable benefit of the OneLake from my time in the tool is the quick load data feature available in the OneLake UI. This feature allows you to load data into a DataFrame variable inside a notebook directly from the UI, giving analysts quick access to the data they need to find insights. Just be careful to make sure you don’t overwrite another DataFrame variable in the same notebook, as by default these are all named ‘df’.
Multiple Lakehouses
Within OneLake there is the ability to create multiple lakehouses in various workspaces. These all sit within the same physical OneLake. Each lakehouse shows at its own artifact, and data is separated at this logical level, whilst still living inside of the same underlying lake. This can provide security benefits by allowing organizations to keep potentially sensitive data separate and have its own access control policies. Different workspaces allow different parts of the organization to work independently while still contributing to the same data lake. Each workspace can have its own administrator, access control, region, and capacity for billing. This distributed ownership approach can help organisations of all sizes simplify their access policies and enforce the correct level of access from the outset. This is all made possible by the OneLake architecture. See below how these workspaces and lakehouses can give a logical separation of datasets and security.

OneLake with multiple lakehouses for several business divisions
Familiar user experience
Finally, one of the other benefits of the OneLake is the fact that it is part of the power platform. This means that users have access to a familiar experience, with a consistent look and feel across all the tools and features available in the platform. This can help to reduce training time and increase adoption rates, as users are already familiar with the overall platform and can focus on learning the specific lakehouse features they need to use.
Conclusion
In conclusion, OneLake stands as an essential solution in the data engineering landscape, effectively addressing numerous daily challenges faced by data professionals. Its automatic provisioning for every Fabric tenant and ability to provide unified data storage across Azure, Amazon and more makes it a practical choice for data management. By supporting both managed and unmanaged data, it creates an adaptable platform for diverse data needs. From utilising the open-source delta file format to offering power-packed PowerBI support, OneLake provides a multitude of capabilities designed to optimize the data workflow. Further, its innovative features like quick data load, ability to create multiple lakehouses within a single physical OneLake, and a familiar user experience contribute to a reduced learning curve and enhanced productivity. Thus, by exploring and harnessing the power of OneLake, organisations can redefine their data management strategies for improved efficiency and insightful business outcomes. If you’d like to learn more, we’re more than happy to have a chat about how Fabric could benefit your organisation. Contact us today to get the ball rolling.