

MLOps - Hints and Tips for more Robust Model Deployments
Introduction
Machine learning (ML) model deployment is a critical part of the MLOps lifecycle, and it can be a challenging process. In the previous blog, we explored how Azure Functions can simplify the deployment process. However, there are many other factors to consider when deploying ML models to production environments. In this blog, we'll delve deeper into some of the essential hints and tips for more robust model deployments. We'll look at topics such as proper model versioning and packaging, data validation, and performative code optimisations. By implementing these practices, data scientists and ML engineers can ensure their models are deployed efficiently, accurately, and with minimal downtime.
Model Management
One of the problems with the implementation from the last blog was that it did not have any model management - the model which was being queried was just a pickle file that was loaded and queried. This is not robust. If the model were to be retrained or changed, then the function would need to be redeployed to contain the new model. It would become very easy to lose track of the most updated version of the model and run the risk of accidently putting an outdated model into production. Fortunately there is an easy solution to this, MLflow!
MLflow
MLflow provides a streamlined way to package and deploy ML models to production environments. Once a model has been trained and evaluated, it can be registered in the MLflow Model Registry, which serves as a central repository for managing and versioning models. Once a model is registered in the MLflow Model Registry, it can be deployed using various tools and platforms, including Docker containers and most importantly cloud services like Azure Functions! This flexibility allows users to deploy models in the environment that best suits their needs, whether it be on-premise or in the cloud.
The MLflow platform provides several features that make deploying models to production more straightforward and reliable. For example, MLflow's model versioning capabilities enable users to track the history of each model, including the metadata and parameters used to train the model. This feature makes it easier to manage different versions of a model and roll back to a previous version if necessary. MLflow's model packaging, versioning, and deployment capabilities, combined with its data validation and performance monitoring features, make it a valuable tool for deploying ML models to production environments. By using MLflow, data scientists and ML engineers can streamline the deployment process, reduce errors, and ensure more reliable and effective ML deployments.
Implementation
Given the model used is an SKLearn model, the MLflow instance is managed by Databricks so it couldn’t be easier to connect and load the production model. Simply import the MLflow library, connect using the “databricks” as the URI (which will take the host and token from the local machine or configured secrets in the Azure Function automatically), and load the model by name using the Production tag. In the advanced implementation this is all packed up into a neat little function so it can be called whenever needed. Using this method if a new version of the model is trained, it simply needs its stage changed to Production, and the function will load it without any need to change the code or redeploy the function.
import mlflow
from mlflow.tracking import MlflowClient
# Setup the MLFlow client
mlflow_uri = "databricks"
client = MlflowClient(tracking_uri=mlflow_uri)
mlflow.set_tracking_uri(mlflow_uri)def load_model():
"""
Function to load the model from MLFlow and assign it to the global MODEL variable
"""
model = mlflow.sklearn.load_model(model_uri="models:/sk-learn-Random Forest-reg-model/Production")
logging.info("Successfully loaded model sk-learn-Random Forest-reg-model from MLFlow")
return modelData Validation
Another problem with the implementation in the last blog was that, although it returned errors and told users where problems occurred, it didn’t give much information on what the problem was or how it could be fixed. This is particularly important if the issue is with the data being passed into the model; if a user doesn’t know they are providing the wrong data there isn’t much that can be done, fortunately a Pydantic offers the perfect solution to this problem!
Pydantic
Pydantic is a Python library that provides data validation and settings management capabilities. It allows users to define data schemas or models with well-defined fields and types, and then validate incoming data against those models. Pydantic's data validation capabilities are particularly useful for data science and machine learning applications, where data quality and consistency are critical. With Pydantic, data scientists and developers can easily define the structure and types of incoming data, and then validate that data to ensure that it meets the required criteria.
In addition to data validation, Pydantic provides a range of other features, including:
Type conversion: Pydantic can automatically convert incoming data to the correct type, such as converting a string to an integer or float.
Default values: Users can specify default values for fields in their data models, which will be used if no value is provided.
Data parsing: Pydantic can parse and validate data from a variety of sources, including JSON, YAML, and TOML.
Settings management: Pydantic can be used to manage application settings and configuration, allowing users to define a set of parameters that can be easily modified and accessed from anywhere in their application.
Implementation
Even just using the most basic functionality of Pydantic can add a huge amount to the quality of the model deployment. The example below imports the necessary classes and then builds a data structure for the model, a simple Iris classification model that accepts four decimals as its input. It really is that easy to define a data structure using Pydantic! The final snippet shows how this is implemented into the main body of the function. Very simply, we create an object of the new model using the json input data and wait for it to throw any errors and tell us that there is a problem. If there are no errors then the job is done, the data is validated and the function can move on to pre-processing and model querying! ValidationError is an extremely thorough type of error message so very little processing is required, it can just be returned to the user and will explain to them what needs to be fixed.
from pydantic import BaseModel, ValidationError
...
class IrisInput(BaseModel):
"""
Class to define the structure for the Unemployment model input data
"""
Sepal_Length: float
Sepal_Width: float
Petal_Length: float
Petal_Width: float
...
# Validate the input
try:
IrisInput(**json_msg)
logging.info("Input validated successfully")
except ValidationError as e:
logging.error(f"Message validation failed, {e}")
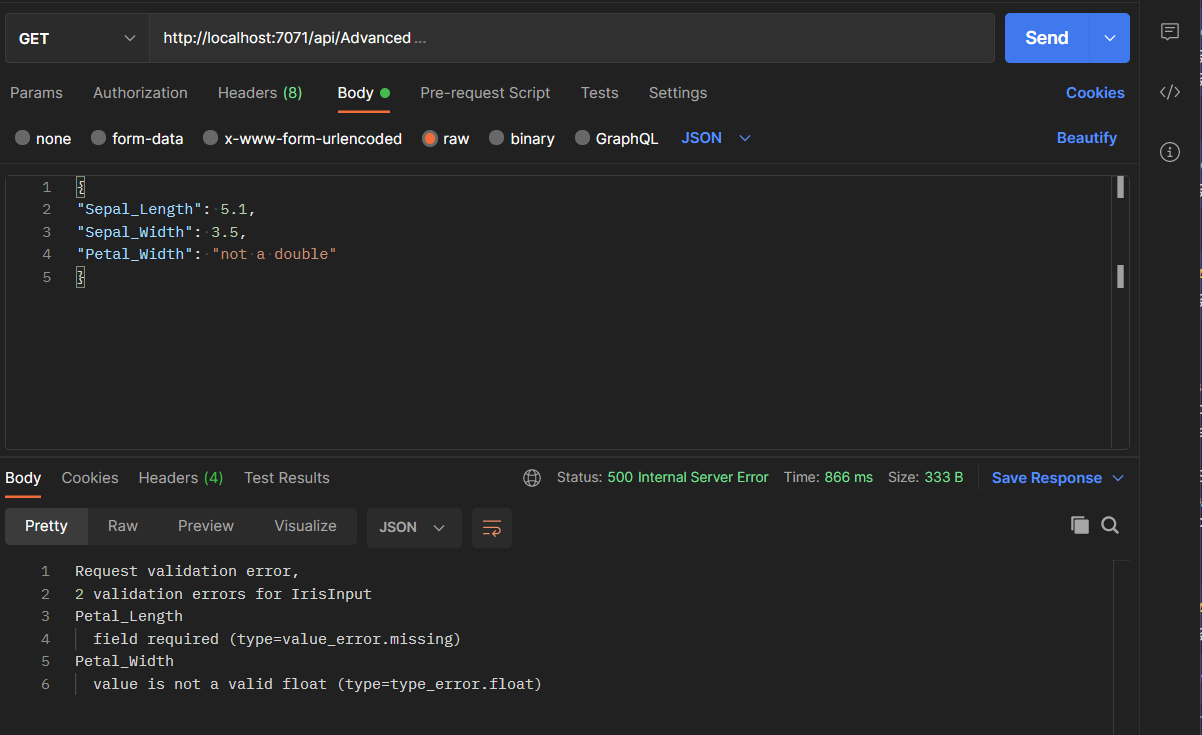
return return_error(f"Request validation error, {e}")The screenshot below is a great example of why having data validation is fantastic for making model deployments more robust. From the message body we can see that the data passed to the endpoint is not the four doubles required by the Iris classification model. However rather than returning some vague error message the response body contains precise information on what the problem is. It tells us that the number of problems, 2, and what they both are. Firstly that petal length is missing, which it clearly is, and secondly that petal width is not a float. Which again it isn’t, it is “not a double” which is a string!
Better Performance & Less Downtime
The last problem with the implementation from the last blog, as was alluded to earlier, is the way the model is handled. We have looked at how loading a pickle file stored locally is not a fantastic idea, but it also included a lot of wasted time having to load the model each time the function is called. By making the model a global variable it only needs to be loaded once and will then persist in memory while the instance of the function exists. “But what is the model changes, if it is a global variable we can’t reload it without restarting the function, taking us back to square one?” A good question, and one that can be easily addressed through a little route parameter wizardry.
Global Models
It is a very easy change to the existing code to make the model a global variable, just use the global keyword! Done. Now after the load_model() function is called for the first time the model will persist in the given instance of the function and won’t have to be loaded every time it is called. When using MLflow for model loading this is a big performance boost as it can take a couple of seconds to load the model and doing this every time it is called quickly increases the compute time and therefore also the cost! The last change that we need to make is to add something into the function main to make sure that there is always a model loaded, and load one if there isn’t. It is as easy as doing a check to ensure the model has a none null value, and calling the load_model() function is it is.
# Create variable to store the model
MODEL = None
...
def load_model():
"""
Function to load the model from MLFlow and assign it to the global MODEL variable
"""
global MODEL
MODEL = mlflow.sklearn.load_model(model_uri="models:/sk-learn-Random Forest-reg-model/Production")
logging.info("Successfully loaded model sk-learn-Random Forest-reg-model from MLFlow")
...
# If there is no model loaded, load the model
if MODEL == None:
try:
logging.info("Loading model")
load_model()
except Exception as e:
logging.error(f"Failed to load model, {e}")
return return_error("Failed to load model")Reload Parameter
Putting everything together we now have a deployment that will load a production model from MLflow and store it as a global variable to reduce computation times when the function is called. The only remaining challenge to be solved is how to make it so that the model can be reloaded without having to restart the function. All that is really needed is some sort of trigger that can be sent to the function to get it to call the load_model() function on demand to reload the latest model into global function variable.
There is no ‘right’ way to do this, but adding a route parameter with the purpose of triggering a reload is the method of choice here, as it is simple and makes it clear exactly what will happen when it is called. There are two steps required to set this up, the first is to add a new line to the bindings in function.json, the line is: "route": "Advanced/{reload?}" replacing advanced with the name of the function if this is for a different one. Secondly an addition needs to be made to the function main to look for a that parameter, call the reload if it is found, and then end the function early. This is shown in the code snippet below.
function.json:
"bindings": [
{
"authLevel": "admin",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
],
"route": "Advanced/{reload?}"
}__init__.py
# Check if reload was called
reload_flag = req.route_params.get('reload')
if reload_flag == "reload":
try:
logging.info("Reloading model")
load_model()
except Exception as e:
logging.error(f"Error loading model, {e}")
return return_error("Error loading model")
# If the model is successful reloaded return a 200 response
return func.HttpResponse(body="Model successfully reloaded",
headers={"Content-Type": "application/json"},
status_code=200
)Conclusion
And just like that, we have taken the model deployment to the next level, ensuring it is robust, reliable, and fast! MLflow provides a powerful model registry and deployment platform that can help manage the entire model lifecycle, from experimentation to deployment. With its support for a wide range of machine learning frameworks and libraries, MLflow makes it easy to track, and compare models in a variety of environments. Similarly, Pydantic can help validate and enforce data schemas, making it easier to catch errors and ensure that deployed models are working with the correct input data. Using Pydantic to validate the inputs and outputs, reduces the risk of errors and ensure that the models are performing optimally in production.
To see the full code implementation you can find the GitHub repo here, which includes instructions on how to setup the functions and run them yourself! Stay tuned for the final blog in the series where we will explore more advanced model architectures, delve into the world of durable functions!
If you want to learn more about how we can help you get up and running with MLOps and get models into deployment you can find out more about our services here.