What’s the difference between a data lake and a data warehouse? Data lakes can house native, raw data, while data warehouses hold structured data that is already processed.
Determining which data storage environment—data lake vs. data warehouse—your business needs depends on what type of data you want to work with and the objectives of your data strategy. You’ll likely find your organization needs both solutions.
What Is a Data Lake?
Data lakes are data storage environments that can hold a vast amount (think: petabytes) of structured and unstructured data and semi-structured data sourced from relational and non-relational databases and business applications.
Data lakes are aptly named because they allow those who work with big data, like data scientists, business analysts, and data engineers, to dive deeply into and experiment with all available internal and external data an organization channels into the lake, which can include information in its data warehouses.
Data lakes can provide quick access to diverse data sets, including log files and financial reports, in various formats for performing data analytics within the data lake environment. And because you can store data at any scale in a data lake, these solutions are ideal for processes that require the intake of massive amounts of data, like predictive analytics and machine learning.
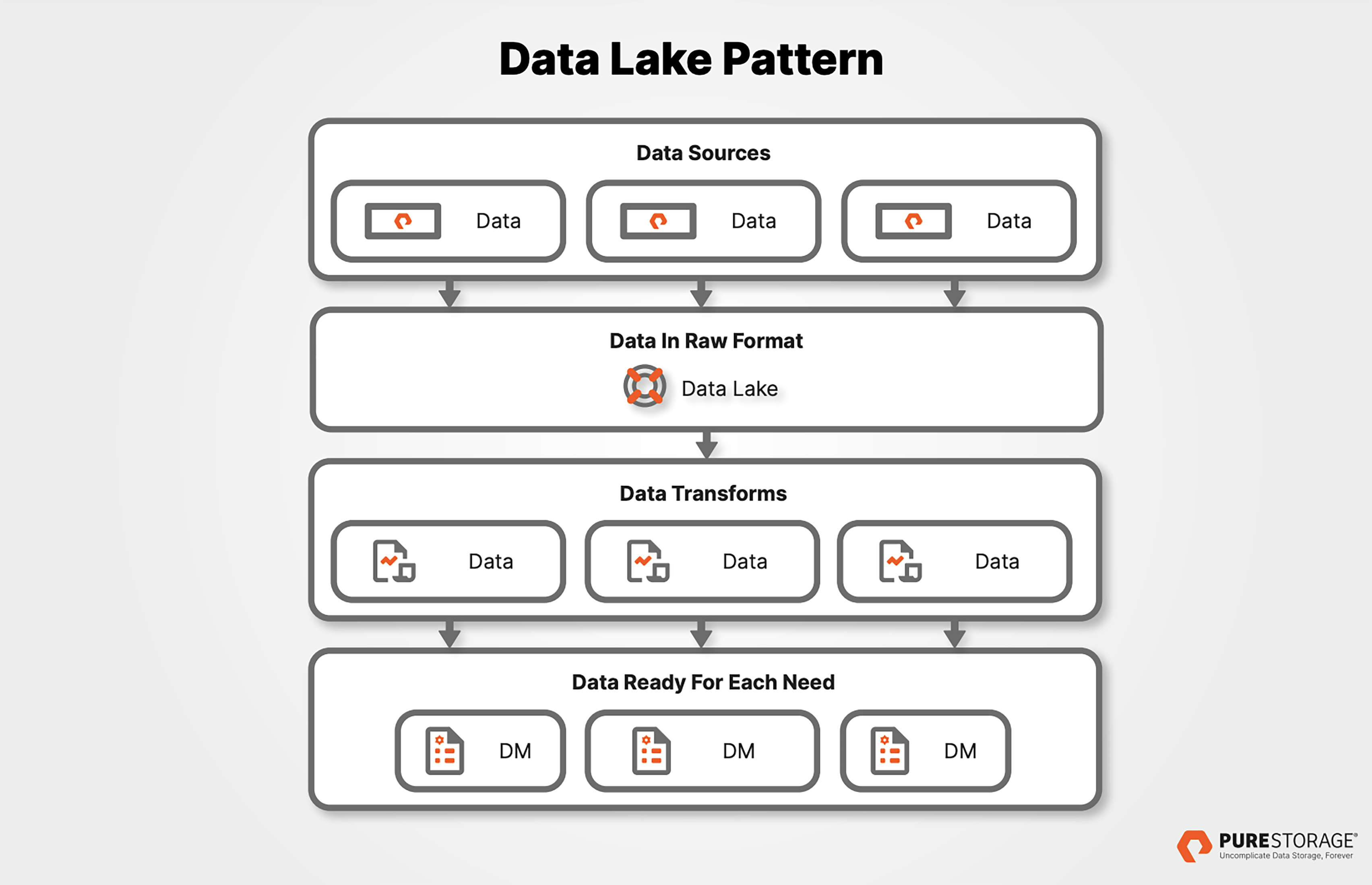
Data Lake Diagram
To extract business intelligence insights from the raw data sources in a data lake, the data must be processed (aka transformed) using advanced analytics tools and then transferred to another environment, such as a data warehouse or a data mart. Users of applications, such as data visualization tools, and business systems like databases, can then work with that data.
The following diagram provides a high-level overview of this process:
Data Mart vs. Data Lake
A data mart is mentioned above—but what is it? While data marts and data lakes are both systems for storing data, data marts are more akin to data warehouses because they hold processed data. Data marts are databases that hold a limited amount of well-structured data to serve the needs of a specific business function, like the finance department.
Data Lake Examples: Cloud and on Premises
You can implement a data lake in two ways: in the cloud or on premises.
With a cloud data lake, you’ll work with a provider—AWS, Microsoft Azure, and Google are examples—that hosts your data lake on its platform and handles all the details like managing security and backing up your data. You can access your cloud data lake via the internet, and you’ll likely pay the provider for services via a subscription-based model. Many companies choose to set up cloud data lakes because they’re less labor-intensive and allow the business to focus more on working with its data.
On-premises data lakes, meanwhile, are a heavier lift, as companies need to buy and implement the hardware and software to set up and maintain them. They also need to invest in hiring specialists, like data engineers, to manage the data lake, and ensure it’s secure and performing optimally. Space and power needs are also major considerations with on-premises data lakes. In short, this approach is often very resource-intensive—which is why many organizations today head straight for the cloud when they need to create a data lake.
What Is a Data Warehouse?
Back to comparing a data lake vs. a data warehouse, here’s a quick definition of the latter: A data warehouse is a repository for integrating and storing structured data, like spreadsheet data, pulled from multiple data sources across an organization.
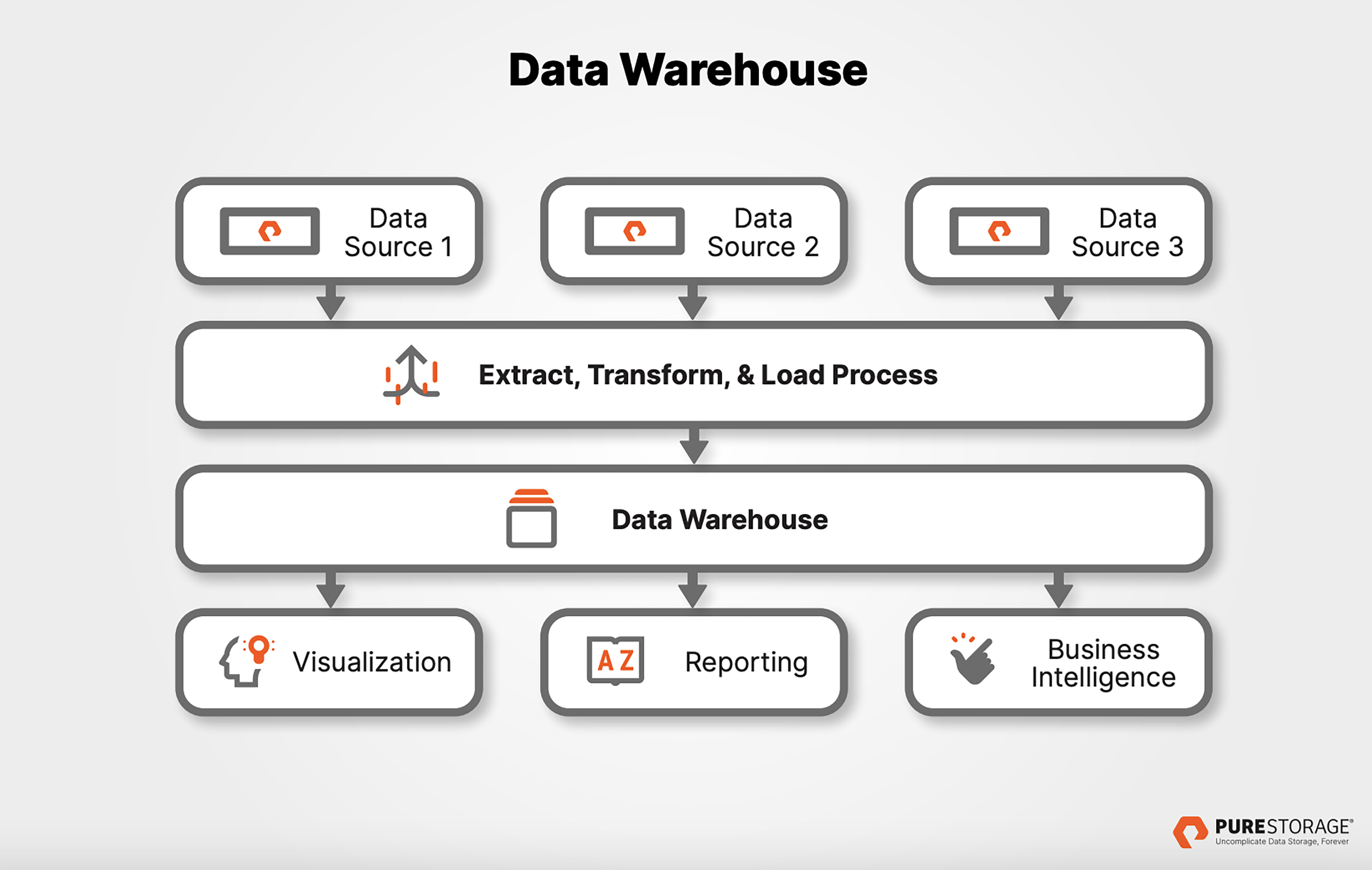
Data Warehouse Diagram
Data warehouses take in information from various sources through the Extract, Transform, and Load (ETL) data integration process. Sources of data for a data warehouse can include transactional systems and relational databases—and data lakes, as well. Businesses use the processed data in data warehouses to perform high-speed SQL queries for generating business intelligence (BI), data visualizations, and reporting.
Data Warehouse Examples
Types of data warehouses include the following:
- Enterprise data warehouse (EDW), which centralizes an organization’s data and makes it accessible to everyone in the business who needs it for analytics and reporting. An EDW can include one or more databases.
- Operational data store (ODS), which integrates data from multiple sources. An ODS is used primarily for querying transactional data, which is often refreshed in real time.
Another data warehouse type, mentioned earlier in this article, is a data mart. It’s considered a subset of a data warehouse. Data marts are smaller (under 100GB) and designed for a particular business unit to use, like the marketing department. In contrast, a data warehouse can serve an entire organization and exceed more than 1TB in size.
Database vs. Data Warehouse
What is the difference between a database and a data warehouse? While a data warehouse is, technically, a database, it exists so that organizations can perform analytics on the data within it.
A database isn’t designed for analytics; it stores data from one source and is used to process simple queries.
Data Warehouse vs. Data Lake: How Data Is Stored
Data is stored in a data warehouse via the ETL process mentioned earlier. Data is extracted from various sources, it’s transformed (cleaned, converted, and reformatted to make it usable), and then, it’s loaded into the data warehouse where it’s stored hierarchically in files and folders.
Data lakes, which have a flat architecture, can receive raw data from various internal and external data sources, including social media and mobile apps, intelligent sensors, websites, and more. Data lakes store this data as files or object storage. The latter describes data stored in discrete units (objects) that have unique identifiers or keys, which allows them to be found no matter where they’re stored on a distributed system.
Want more? Read: Pure Storage and Snowflake Hybrid Cloud Solution
Data Warehouse vs. Data Lake: How Data Is Accessed
Data in data lakes can be accessed using open source frameworks like Apache Hadoop and Apache Spark, and other tools and frameworks provided by commercial vendors that are designed for processing and analyzing large data sets.
As for data warehouses, users can typically access the data within them using BI tools, dashboards, and applications. Direct SQL access is also widely used for connecting directly to data in the warehouse and to run queries.
How Data Lakes and Warehouses Work Together
Data lakes and data warehouses complement each other and often sit together in an organization’s data infrastructure, including in the cloud. With a data lake, the business can experiment with data and pull insights from it before transforming it so it can be moved into purpose-built systems—like a data warehouse—and used more directly by the organization.
Can a Data Lake Replace a Data Warehouse?
The short answer is no. Data warehouses and the processed, refined data they contain play a critical role in supporting everyday data decision-making for the business—and making analytics accessible to many people across the organization.
Data lakes are essentially testing grounds for data scientists, business analysts, and data developers who want to experiment with available data in any format and explore its potential for delivering insights to the business. Data lakes also support data-intensive processes like training artificial intelligence (AI) models.
How to Choose Between a Data Lake and a Data Warehouse (or Not)
Many organizations contemplating the data lake vs. data warehouse question are likely to find that in the long run, they won’t have to choose. Even if they aren’t ready to start working with large sets of unstructured data today or experimenting with emerging technology like machine learning, they will likely need to do so in the future—and they will need both a data lake and a data warehouse to meet their needs.
If your business isn’t prepared to set up and manage both solutions yet, it’s still valuable to understand the difference between a data lake and a data warehouse and when to use them:
When to Use a Data Lake
If your organization is collecting vast amounts of data in various formats from many sources, and you don’t need to access or query that information right away, storing it in a data lake is a good move. It’s more cost-efficient than processing that data and storing it in a data warehouse (if that solution can even take in the data types you want to store). Plus, if you want to experiment with your data, and use it for data-heavy processes like AI, a data lake can support those needs.
When to Use a Data Warehouse
Finally, if your organization wants to access reliable, quality data quickly and easily to support more informed and accurate business decision-making, a data warehouse is a logical data storage solution. A data warehouse lets you consolidate processed data, including historical data, from many sources, and then get quick answers from it using predefined questions. It can help enable the delivery of fast insights and reporting that drive competitive advantage.
![]()