


Here at Pure Storage, we work with a broad range of customers to help them solve their biggest data challenges. For many, the amount of data that is critical to their business is constantly growing. We often work with these customers in search of more efficient tools and processes to improve time to insight and bring greater efficiencies into their operations. To that end, I recently had the opportunity to implement and validate SQreamDB with FlashBlade//S™ for a customer environment that will eventually see petabytes of hot data in production.
Analyzing large datasets requires moving large amounts of data from storage to the compute layer as quickly as possible. This is a job easier said than done as there are many hidden bottlenecks that emerge as datasets grow. A key factor in overcoming these throughput bottlenecks is being able to leverage parallelism at every layer.
In this post I’ll share some field test results and highlight how the parallel nature of both SQreamDB and FlashBlade combine to reduce time-to-insight in large, hot dataset environments.
Product Overview
SQream: SQreamDB is a GPU-accelerated data warehouse and big data platform. SQream is designed for big data analytics using the Structured Query Language (SQL), leveraging NVIDIA GPUs and CUDA for parallelism. It can be a single instance (single node) or clustered. Clustered environments require shared storage and NAS/NFS is fully supported.
Pure Storage® FlashBlade//S: FlashBlade//S is a high-performance consolidated storage platform for both file and object workloads, delivering a simplified experience for infrastructure and data management. The FlashBlade® platform is easy to buy, easy to set up, easy to change, and easy to improve—in moments, not months. FlashBlade provides a high-performance metadata engine to match the high-throughput data delivery for SMB, NFS, and S3 in a simple, scale-out architecture.
Testing Purpose
In support of a customer workload, we configured SQreamDB to use FlashBlade//S™ via NFSv3 in the Pure Storage Customer Success Center (CSC) POC lab. The scope of the testing was primarily to validate the functional operation as well as to understand the storage performance requirements of a typical workload.
The workload chosen was TPCx-BB, aka “Big Bench,” due to the broad industry applicability, access to the data generation tool, and the ability to compare against pre-existing benchmarks run by SQream on other platforms. While we are running the TPCx-BB benchmark, we are not trying to produce official results or break any records, as this lab was not set up for that. Instead, we’re using the benchmark as a representative workload to validate all components working together and compare results.
The goals of this testing were to:
- Validate that SQream software functionally works with FlashBlade over NFS.
- Ensure FlashBlade over NFS with nconnect is able to deliver the required throughput/performance to the GPU database under load.
- Understand the workload characteristics to inform storage performance sizing decisions.
Data loading was performed but not optimized due to time constraints.
Test Plan and Methodology
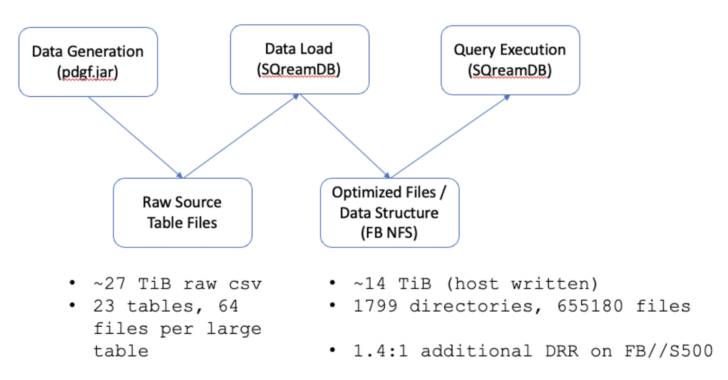
Data Generation
Data was generated using the TPCx-BB-provided parallel data generation framework (pdgf) tool included in the benchmark kit. This tool creates the raw source tables, in a CSV-like format, to be loaded into the database.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
[root@dgx ~]# cat /root/sqream/data-generator/tables.txt customer_address income_band product_reviews store_returns web_page customer inventory promotion store_sales web_returns customer_demographics item reason time_dim web_sales date_dim ship_mode warehouse web_site household_demographics item_marketprices store web_clickstreams # add commands to a job file and let `parallel` do the job management SF=30000 NC=64 for TABLE in $(cat /root/sqream/data-generator/tables.txt); do for NN in $(seq 1 $NC); do echo java -jar /root/sqream/data-generator/pdgf.jar -sf $SF -s $TABLE -nc $NC -nn $NN -c -ns -w 1 -o \"\'/mnt/tpcraw/${TABLE}/\'\" >> jobs done done parallel --bar --jobs $(nproc) --resume --resume-failed --joblog parallel.log < jobs |
These record counts were validated against the row count table from the benchmark documentation (page 36).
Data Loading
During data loading, the raw table entries are read by the database, compressed and indexed by the database, and then written in a custom file format to the FlashBlade over NFS as the internal/primary storage for the database.
As expected, parallel data loading completed in much less time, though this was not the focus of our testing.
Query Execution
A subset of the queries in the benchmark were run. Those queries were 5, 6, 7, 9, 11-17, and 20-26. Note that some of the queries in the benchmark are Hadoop specific and therefore omitted as they are not applicable to this environment.
Testing/Lab Overview
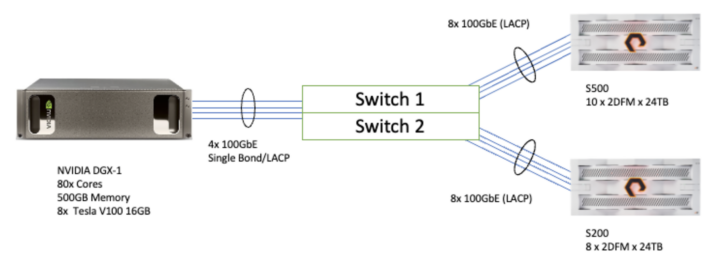
All testing was done in the Pure Storage Customer Success Center (CSC) POC Lab environment, with the following resources:
DGX-1
- RHEL 8.6 (Kernel 4.18.0-372.9.1.el8.x86_64)
- CUDA 11.4.3
- 4x 100GbE, single bond, layer3+4 xmit_hash_policy
- FlashBlade mounted with nconnect=16
- SQream DB version v4.3.1_rh
FlashBlade//S500
- 10 blades, 2 DFMs each, 24TB per DFM
- Purity//FB 4.1.5
- 8x 100GbE LACP/MLAG
FlashBlade//S200
- 8 blades, 2 DFMs each, 24TB per DFM
- Purity//FB 4.1.6
- 8x 100GbE LACP/MLAG
Test Results and Observations
File/Directory Structure on NFS
During data ingestion / loading, SQreamDB divides the data into chunks which are further grouped into extents. These chunks and extents are written as files in a shared file system and split across many directories.
These chunk files are tracked internally via a RocksDB KV store. This chunk metadata is collected for identifying column values and potentially skipping accessing them, to reduce unnecessary I/O operations. For example, when a query specifies a filter (e.g. WHERE or JOIN condition) on a range of values that spans a fraction of the table values, SQream DB will optimally scan only that fraction of the table chunks.
The downside of this data layout, however, is that it creates millions to billions of files for its internal tables. A large file count environment like this typically means there is a higher ratio of metadata to data which is known to slow down traditional storage systems, especially those based on file systems.
FlashBlade was designed with this high metadata ratio in mind and does not have a file system at its core. This makes it uniquely suited for these types of high file count and high performance analytics environments.
This distribution of data records across multiple directories and files allows for parallel processing at the compute/query layer as well as the network and storage layers (assuming the storage system was designed for this type of parallel access, as FlashBlade//S is). The internal metadata tracking reduces the amount of IO needed to the shared file system and improves overall performance.
More detailed information about the data layout can be found here and here.
Optimized data layout in file system:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
[root@dgx tables]# pwd /mnt/s500/sqream/sqream_storage/databases/master/tables [root@dgx tables]# tree ... 1799 directories, 655180 files [root@dgx tables]# tree | head -n 20 . ├── 0 │ ├── 0 │ │ └── 0-0 │ ├── 1 │ │ └── 1-0 │ ├── 10 │ │ └── 10-0 │ ├── 11 │ │ ├── 11-0 │ │ ├── 11-102 │ │ ├── 11-123 │ │ ├── 11-144 │ │ ├── 11-164 │ │ ├── 11-184 │ │ ├── 11-205 │ │ ├── 11-21 │ │ ├── 11-225 │ │ ├── 11-246 │ │ ├── 11-41 ... |
Data Reduction
The raw source table files from the pdgf.jar data generator created ~27TiB of data. This was reduced to 13.91TiB written by SQreamDB after loading and compressing into internal table files. FlashBlade further reduces this data using its always-on, built-in compression. The data written and the data reduction below is specific to the data set generated by the pdgf.jar tool. Data reduction efficiency will vary based on the data type.
|
1 |

Storage Performance Baseline
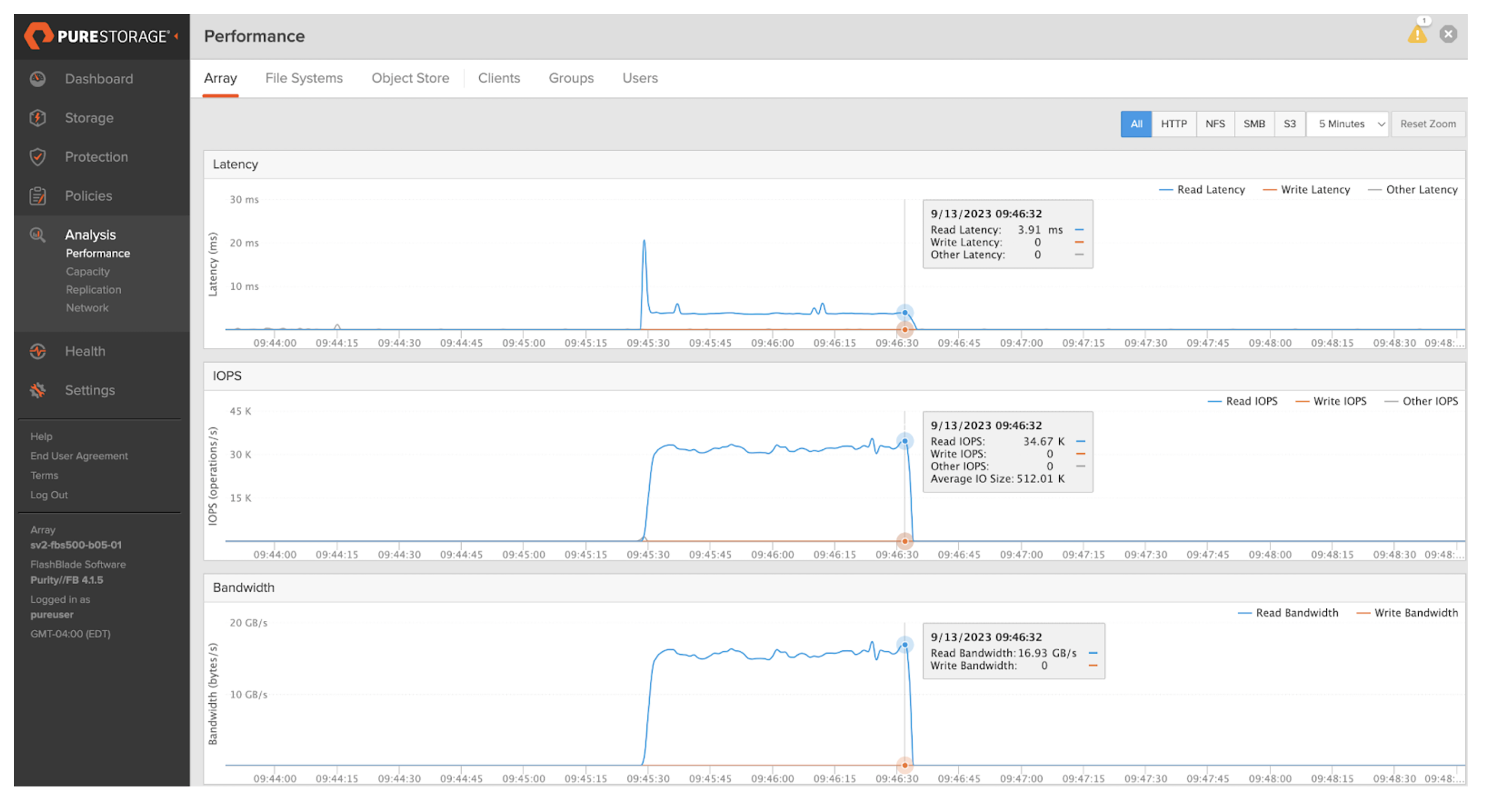
Fio was used to get a quick storage throughput baseline with the S500 mounted to the DGX-1. This shows ~16GB/s with 100% reads is possible with a single node with a single mount point using the nconnect mount option.
|
1 2 3 |
FIO_NUMJOBS=512 fio --name=fiotest --directory=/mnt/s500/jlay1/fio/ --size=8G --rw=read --bs=512K --direct=1 --numjobs=$FIO_NUMJOBS --ioengine=libaio --iodepth=256 --group_reporting --runtime=60 |
Storage Load
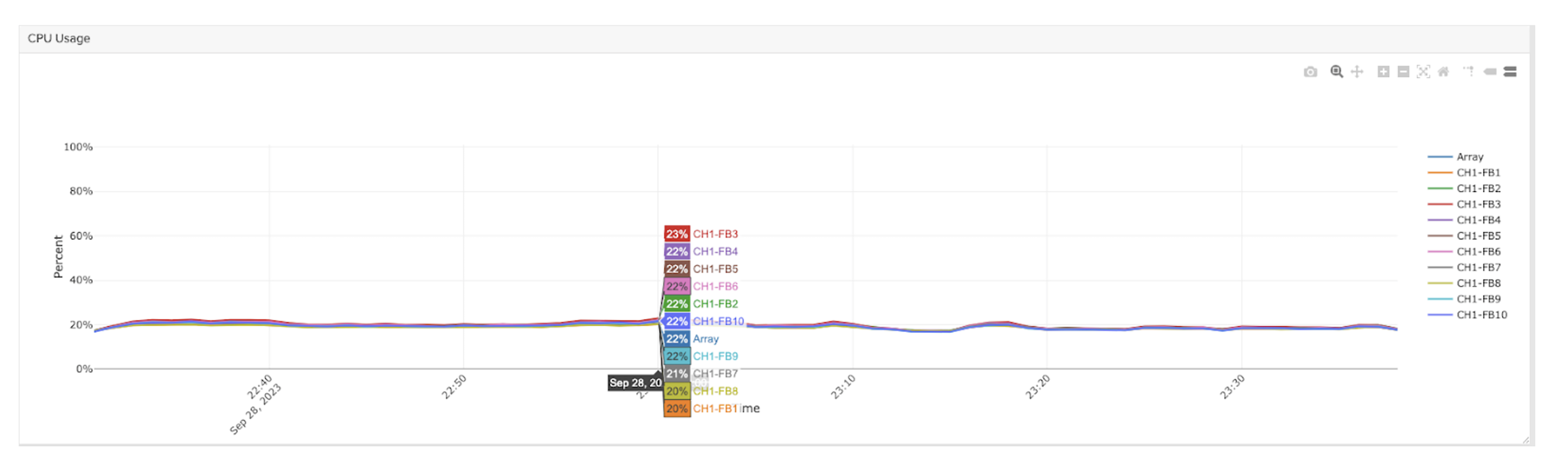
During the SQreamDB query workload, both the S500 and S200 were observed to have plenty of CPU headroom available for additional IO processing. Here we can see the S500 CPU utilization peaking at around 27%.
Importantly, we observe that all storage blades are evenly utilized. This means the IO is evenly distributed (parallelized) across all available blades and network paths which avoids “hot spots” on any given resource which could limit performance.
S500 blade CPU utilization:
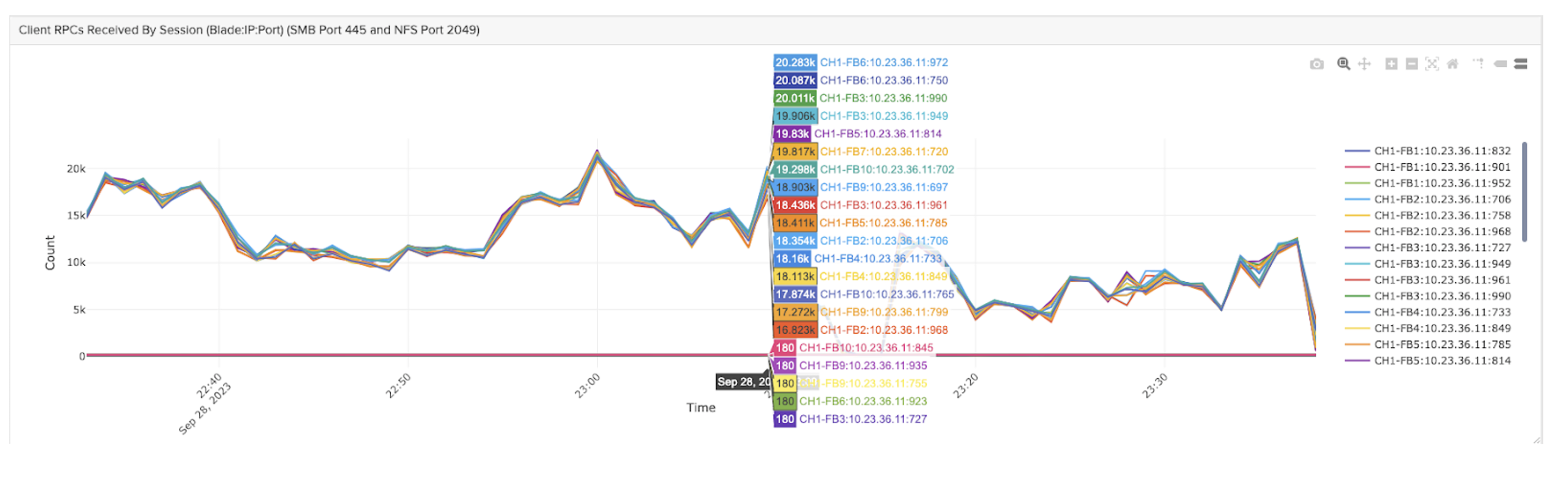
NFS nconnect
Mounting FlashBlade with nconnect=16 works extremely well. You can see below the even balance of NFS RPCs across all 16 client TCP connections.
Nconnect allows the client to take advantage of the performance of multiple blades simultaneously through a single mount point on the host. It enables both high performance connectivity and simplicity.
Nconnect is included in Linux Kernel version >5.4 and RHEL Kernel >4.18.0-240.el8 (>RHEL 8.3). There is no additional software to install or upgrade. Nconnect can be enabled by simply adding nconnect=XX in the mount options on supported Kernels.
Data Load Performance
While not the focus of this testing, data loading was measured for both FlashBlade platforms. Data loading throughput on S200 was 5.22TB/hr. Data loading throughput on S500 was 5.28TB/hr.
The similarities here represent not only some of the best published data loading times for SQreamDB but also that data loading/processing is bottlenecked at the GPUs/CPUs in the DGX-1.
Database Query Performance
Optimized queries were run against both the FlashBlade//S500 and //S200 to get a realistic throughput/completion time that can be used for comparison. Optimized here means some queries were split to run across multiple GPUs simultaneously. All storage metrics noted above were observed during this time.
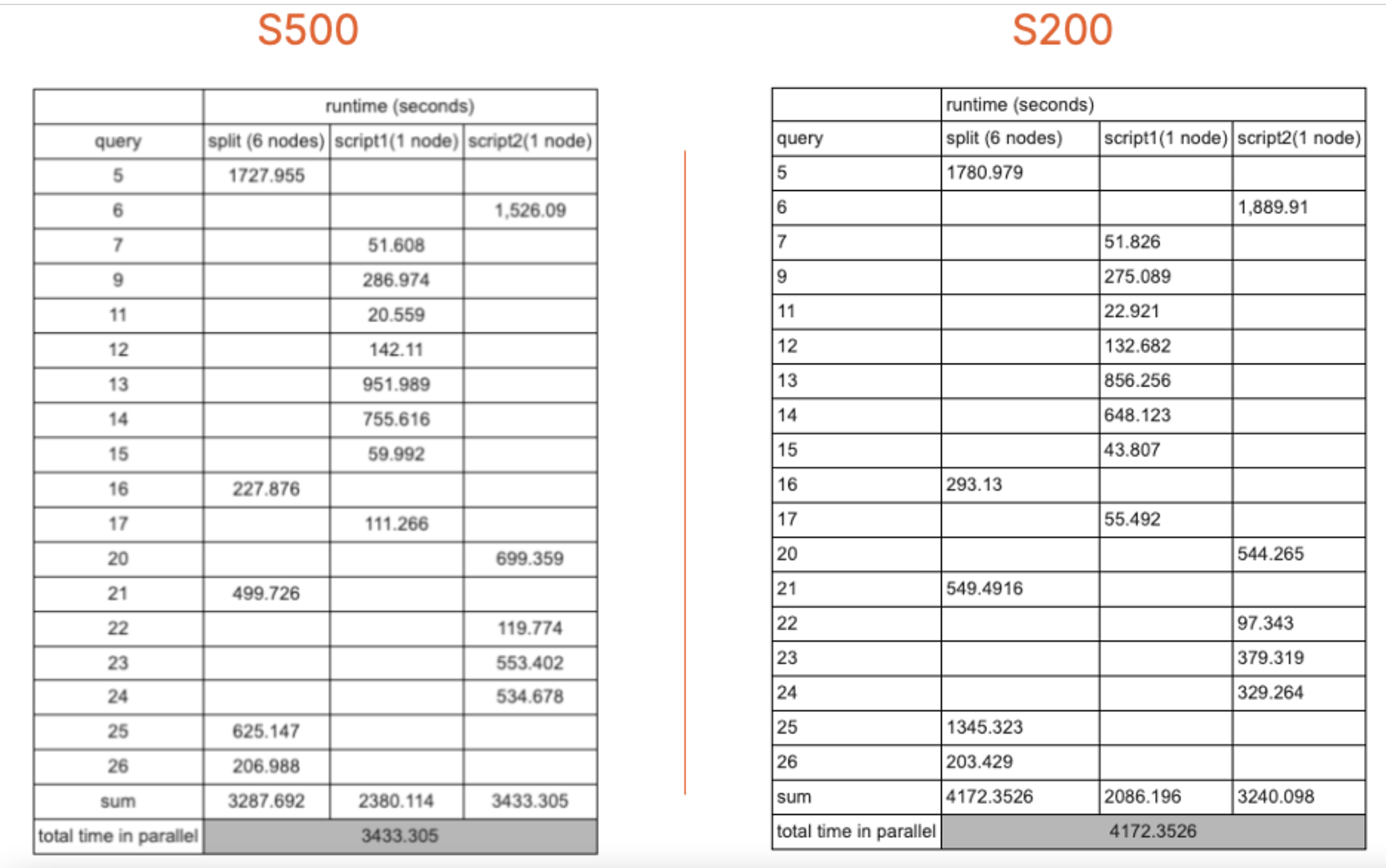
| Runtime (Seconds) | Runtime (Minutes) | Difference (%) | ||
| S500 | 3433.305 | 57.22175 | 21.53% | faster |
| S200 | 4172.3526 | 69.53921 |
For the S500, the queries all completed in ~3,433 seconds, which is ~57.22 minutes. This means the performance of this approximately eight-year-old compute hardware is on par with the cloud-based queries shown in the TPCx-BB 30TB benchmark comparison on the SQream website.
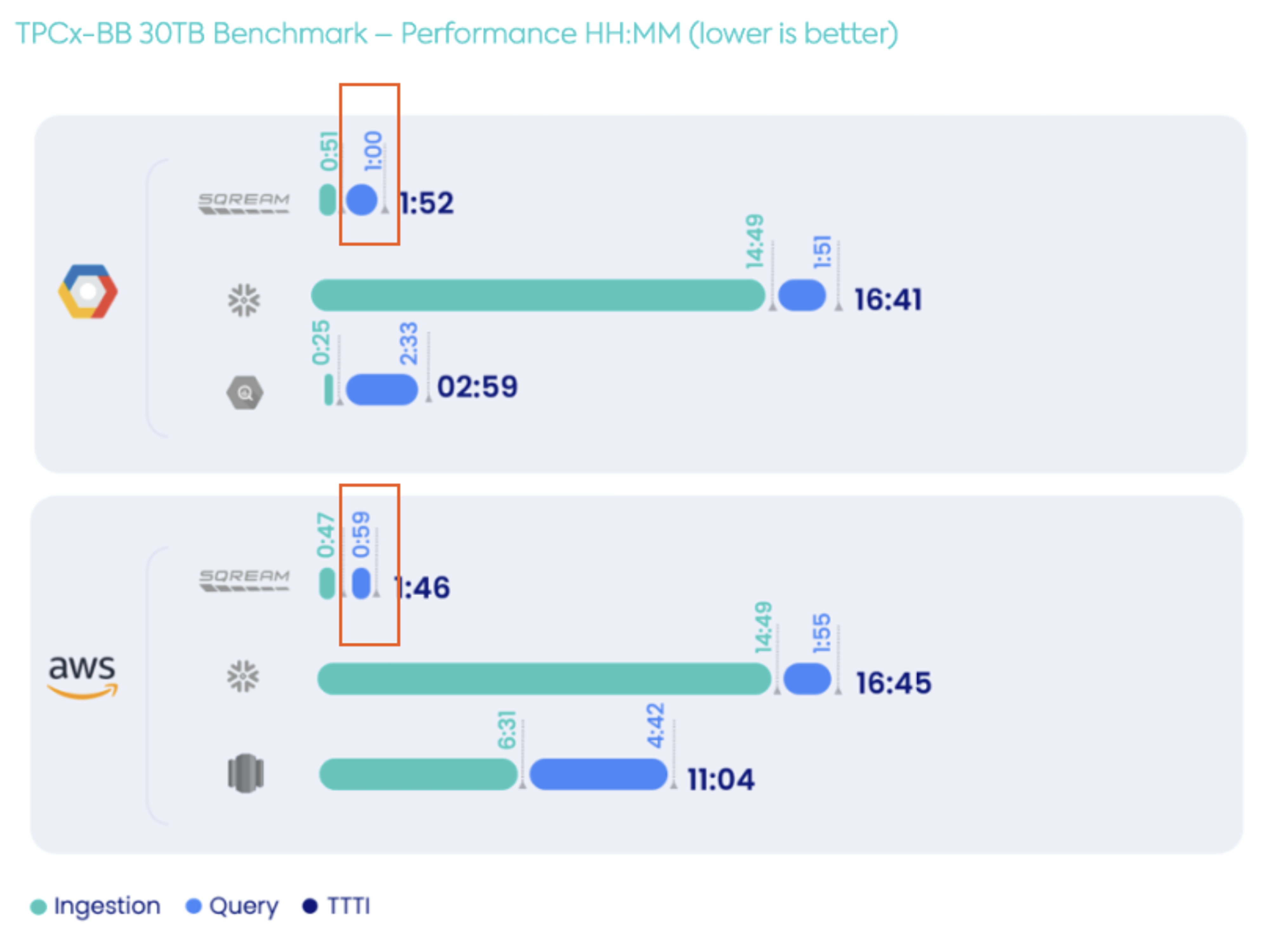
It was noted that the test results published on that web page use NVIDIA T4 16GB GPUs. In the table below, we can see the GCP and CSC Lab GPU configurations are roughly the same, as are the query results/times. Here’s a quick comparison:
| SQream on GCP Configuration | SQream in CSC Lab Configuration |
|
|
Important Note: The type of GPU and CPU will have a significant impact on data loading and query performance. Testing shows the older DGX-1 (CPUs and GPUs) used in this testing was the bottleneck. Newer GPUs (e.g., A100 or H100) with more memory and/or a great number of nodes/GPUs will provide better performance.
Both the S500 and the S200 FlashBlade systems in the lab had more than enough headroom available to deliver additional throughput to the SQreamDB instance. Pure Storage can work with the customer and SQream solutions engineers to size the storage appropriate for the given workload.
Conclusion
Goal #1: The testing confirmed that SQream is optimized to work well with large data sets, and it also creates an “on disk” file and directory structure that is optimized for shared, fast, parallel access across multiple GPUs and nodes. Testing confirms that FlashBlade and SQream not only function well together but also that both are well-suited for these types of “big data” analytical workloads/use cases.
Goal #2: Storage metrics from the TPCx-BB benchmark queries, show we can see that the IO workload generated was easily handled by the FlashBlade S500 and S200 with nconnect in this environment. These queries are compute-intensive and the GPUs/CPUs in the older DGX-1 proved to be the bottleneck in this testing while still matching previous, similar results on other platforms. The additional storage IO processing headroom shows that clusters of SQream GPU nodes can all share a single, highly performant, petabyte-scale namespace.
Goal #3: The S500 delivered a 21% faster query runtime compared to the S200. These results are expected given the improved processing capabilities of the S500 (i.e,. faster CPUs) which leads to lower IO latency. While both FlashBlade hardware platforms perform extremely well, they can be recommended for different use cases. The S500 should be recommended where query performance, aka “time to insight”, is the primary objective. S200 is well-suited for environments where slightly lower query performance is acceptable in exchange for a lower cost—yet still provide the high capacity, high concurrency, and high throughput capabilities to the SQream database.
If you would like to know more about how Pure Storage can help you solve data problems and reach insights faster, please reach out to your Pure Storage Sales team or Partner or use the Contact Form.



