


This is the fourth and final part of this series, which explores using ActiveDR for managing Oracle disaster recovery.
Part 1 : Configure ActiveDR and protect your DB volumes (why & how)
Part 2 : Accessing the DB volumes at the DR site and opening the database
Part 3 : Non-disruptive DR drills with some simple scripting
Part 4 : Controlled and emergency failovers/failbacks
In Part 1, we learned how to configure ActiveDR™. In Part 2, we learned how to build a DR database from our replicated volumes. In Part 3, we used some simple scripting to manage non-disruptive DR testing, and hopefully, this should be all you ever need to meet any regulatory requirements.
Although I’ve been involved in dozens of DR tests, real disaster situations are rare. I’ve encountered them twice in a 16-year period working on infrastructure teams. Nevertheless, they do happen and usually at the most unexpected of times, so we need to be prepared and have the procedures and processes in place to recover business services quickly.
I remember one occasion when an electrician working in the primary data center of my employer in London accidentally took down a power circuit and with it several racks of servers that ran the foreign exchange systems. Luckily, it happened during office hours so the infrastructure teams were on-site and able to respond quickly, and trading resumed within a couple of hours. Even so, the financial loss was significant and the unlucky electrician was not seen again. So, as well as being able to prove our BCP processes work, we need a plan to enact them should a human error occur or in the event of something far more serious such as a natural disaster.
I’ll lay out two scenarios here. The first is a controlled failover which might be a sensible thing to do for various reasons, including some scheduled major electrical work in your primary data center. The second is an unplanned outage requiring an emergency failover that could arise from any number of things, including human error, hardware failure, or natural disaster.
Controlled Failovers with ActiveDR
In this scenario, we know in advance we need to do something risky—perhaps it’s electrical work or a refresh/upgrade of hardware. Whatever it may be, we want to mitigate risk by running our business at the DR site while the work takes place at the primary site. If you’re a Pure customer, you’re already enjoying our Evergreen® business model that eliminates all risk from storage upgrades, but perhaps you’re doing a server upgrade.
The key thing we’re looking for in this scenario is zero data loss. The steps to ensure this are:
- Clean shutdown of PROD applications and database services.
- Demote quiesce the Oracle-PROD pod to ensure all data is replicated.
- Promote the Oracle-DR pod.
- Start DR database services and applications.
This can all be done in the FlashArray™ GUI and on the command line, but you’re most likely going to want to automate this with an orchestration tool or some scripts. You can find some simple shell scripts I’m using on GitHub.
Note: These scripts are for example purposes only. If you wish to use them, be aware that they are not supported by Pure Storage and you should add your own error checking and hardening.
We start with our database and applications running at the PROD site.
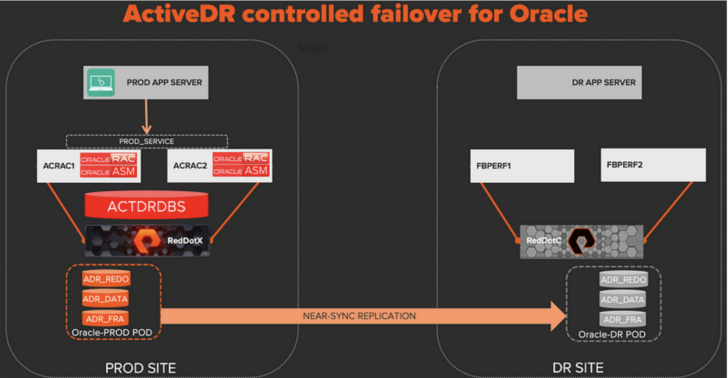
Replication is flowing from the promoted Oracle-PROD pod to the demoted Oracle-DR pod.
On the DR host, I’m using my script dr_controlled_failover.bash to drive the whole process. It makes calls to the PROD host and array to do each of the four steps outlined above and I’ll step through each stage.
On the PROD host, clean shutdown database services and demote PROD pod:
# Stop the PROD Database
srvctl stop database -d ACTDRDBS -o immediate
# Dismount PROD ASM Disk Groups (as the grid user)
sudo su - grid -c 'echo "alter diskgroup ADR_REDO dismount force;" | sqlplus -s / as sysasm'
sudo su - grid -c 'echo "alter diskgroup ADR_DATA dismount force;" | sqlplus -s / as sysasm'
sudo su - grid -c 'echo "alter diskgroup ADR_FRA dismount force;" | sqlplus -s / as sysasm'
# SSH to PROD array to demote the PROD Pod
ssh pureuser@${PROD_FA_IP} "purepod demote --quiesce Oracle-PROD"
This takes less than one minute and now I’m in the state shown below:
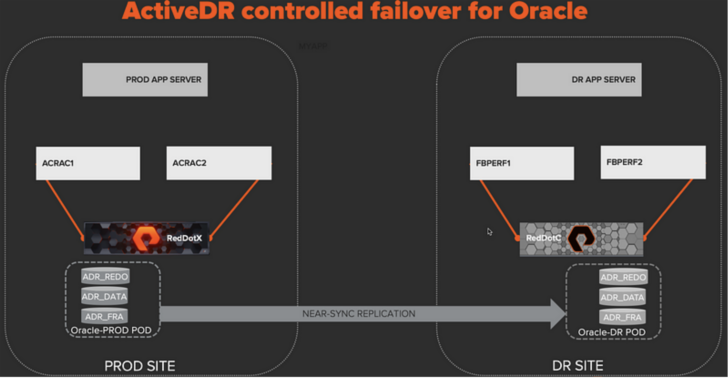
The quiesce option when demoting the PROD pod ensures all data has been replicated to the Oracle-DR pod and the pods at both sites are in sync and in a read-only state.
On the DR host, promote the DR pod and start up the DR database services:
# SSH to DR array to promote the DR Pod
ssh pureuser@${DR_FA_IP} "purepod promote Oracle-DR"
# Mount DR ASM Disk Groups (as the grid user)
sudo su - grid -c 'echo "alter diskgroup ADR_REDO mount force;" | sqlplus -s / as sysasm'
sudo su - grid -c 'echo "alter diskgroup ADR_DATA mount force;" | sqlplus -s / as sysasm'
sudo su - grid -c 'echo "alter diskgroup ADR_FRA mount force;" | sqlplus -s / as sysasm'
# Start the Database
srvctl start database -d ACTDRDBS
This takes about one minute (90% of the time is waiting for the database to start) and I’m now running on the DR site. Notice that the replication direction has now been automatically reversed so any data changes made to the DR database will be replicated back to PROD.
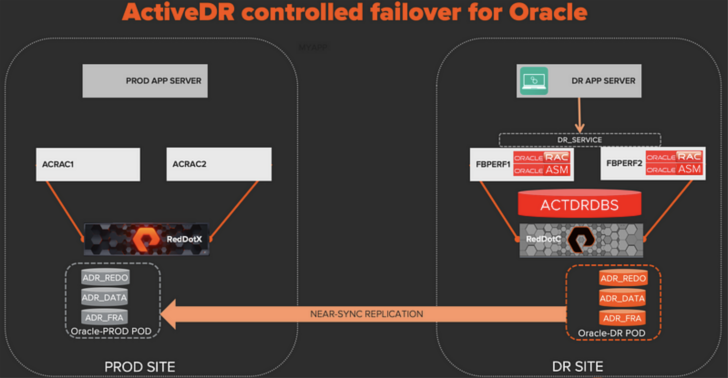
The action of promoting the Oracle-DR pod while the Oracle-PROD pod is demoted reverses the replication direction so that it’s now flowing from DR to PROD.
And that’s it! Super simple—just how we like to keep things at Pure. If I boil this down, aside from the commands to deal with the database shutdown/startup, it’s really just two commands (demote a pod and promote a pod).
To failback to the PROD site, I can use my script dr_controlled_failback.bash, which is essentially the commands shown above but in reverse.
Emergency Failovers with ActiveDR
In this scenario, we’re dealing with an unplanned outage at the PROD site and we’re in an emergency situation where we need to get our business running again as quickly as we can on the DR site.
There’s a lot of different circumstances that could cause this with varying outcomes and I’ll try to cover the most common ones. But, rest assured, whatever the cause and whatever the severity, you can be safe in the knowledge that your DR pods can be promoted at any time to bring up your mission-critical business services in minutes.
Before we get into the different types of failure circumstances, let’s remind ourselves that ActiveDR is an asynchronous replication technology, and although this is a benefit for long-range replication (there’s no performance penalty for writes), it offers a near-zero RPO. Under normal operating conditions and with sufficient replication network bandwidth, the RPO will be in single-digit seconds.
This does mean some in-flight database transactions could be lost in the event of a catastrophic unplanned outage, but Oracle has its own mechanisms for dealing with this and rolling back uncommitted transactions. If you’re looking for a zero RPO solution, then you should check out ActiveCluster™ which provides bi-directional synchronous replication between FlashArray systems operating in a metro area range. So with that in mind, let’s look at some unplanned failure scenarios.
Complete Primary Data Center Loss Caused by a Natural Disaster (Earthquake, Flood, etc.)
Promote the DR pod to resume business operations from the DR site. The original replication link can be removed and a new one can be configured to reprotect data to a new pod on a different FlashArray. If you don’t have access to another FlashArray, you might want to consider taking snapshots of your database volumes and sending them to an on-premises NFS target or to an S3 bucket or Pure Cloud Block Store™ on the public cloud as a temporary measure. Read more about it in my Medium post.
Primary Data Center Outage Caused by a Power Failure
Promote the DR pod to resume business operations from the DR site. If the loss of the primary data center is temporary, then new data added at the DR site will be resynced back to PROD once the PROD array is available again and the PROD pod is demoted.
Loss of Network Connectivity Between Sites
No action is required. Replication data will be queued, and once network connectivity is resumed, queued data will be written to the destination.
Hardware Failures (Servers, Switches, Storage)
FlashArray systems have the highest availability stats in the storage industry with a proven track record of six nines, so assuming the FlashArray is still available and the hardware failure was at the server or network level, then follow the steps from the controlled failover section above. In the unlikely event the FlashArray system is not available, then follow the steps for “Primary Data Center Outage Caused by a Power Failure.”
I’m sure there are many other permutations of different failure scenarios, but these are the main ones we need to be prepared for, and remember, failing to prepare is preparing to fail. Make sure you have a tested plan that is published and well-understood so that everyone knows what to do should the worst happen. Using FlashArray replication features, whether it’s ActiveDR or ActiveCluster, can help you make these plans simple and intuitive. Who wants a complex DR process in the midst of a high-pressure situation to get your business back online? Not me, that’s for sure (you can read Part 1 for context).
![]()



