


This blog on the storage architecture spectrum is Part 2 of a five-part series diving into the claims of new data storage platforms. Click here to read Part 1.
One of my favorite quotes of modern times is about language.
“Almost everything that we think of as dichotomous is, in fact, spectral.” -John Green
We spend so much time trying to put things into categories, and very often, these categories themselves are merely shorthand for much more complicated concepts. Language is inherently less rich than reality, but for simplicity’s sake—for the sake of being able to communicate and describe reality—we tend to put things in boxes. Which leads to silly questions like, “Is a hot dog a sandwich?” when the reality is that sandwiches are an imperfect concept. Most things we think of as simple categories are, in fact, merely a point on a spectrum.
Which is why it is fairly useless to categorize data systems—be they storage, databases, or something in between—into simple, naive categories like “shared nothing” and “shared everything.” In reality, both of these terms attempt to simplify complex architectures and concepts, and using these terms is fairly pointless.
As an example: Two SQL database servers, where one is acting as the primary and the other a secondary, and where each of them uses its own local copy of data, could be considered “shared nothing.” But the same could be said of sophisticated cloud systems like Google’s Cloud Spanner database. Yet these two systems couldn’t be farther from each other on the spectrum of complexity, resiliency, and capability, and very few would question the scalability of Cloud Spanner.
In this installment of our “Beyond the Hype” blog series, you’ll learn more about the diverse spectrum of storage architectures and their tradeoffs, and why Pure Storage products use the architectures they do. And just as important, why there is more to any product or platform than just architecture.
A More Useful Descriptor
One of the more useful ways to approach categorizing these systems is from a recent paper on database architectures by Tobias Ziegler et al. In their taxonomy, the defining characteristic which differentiates systems is how they handle write operations. This makes sense, as in a read-only system, scaling out is trivial. Almost all complexity in scale-out systems comes from how they handle updates. In fact, I’ve gone into great detail about how Purity handles updates and how it was designed for high-update data streams.
In the paper, they define four archetypes of systems: single-writer, partitioned-writer, and two different types of shared-writer (with and without a coherent cache). In our earlier simple two-database server example, this would be a single-writer system, as only one node can issue writes at a time. Conversely, Cloud Spanner in this taxonomy would be considered a partitioned-writer system.
I use these examples to illustrate the huge difference between a simple active-passive database running on two servers and a scalable cloud-native database that gets lost when you describe a system merely as “shared-nothing.” In my opinion, “shared-nothing” means (almost) nothing.
Where is Purity in this taxonomy?
So you may be asking yourself, where does Pure Storage sit on this spectrum with our systems? The answer is we actually use different architectures for different products. Our FlashArray™ family of products leverages a version of Purity (appropriately called Purity//FA), which utilizes a single-writer design. Every FlashArray system has two controllers, each with shared access to DirectFlash® and NVRAM. And while all front-end ports on a FlashArray system are active, only one controller is actively processing IO at any given time. This approach guarantees consistent 100% performance, even in controller failure scenarios. And with Pure Storage’s shared-NVRAM approach, this makes controller failover events completely non-disruptive. This tight coupling of hardware and software makes FlashArray the most simple, resilient system of its kind, and it’s a key experience enabled through our Evergreen® architecture.
For our scale-out FlashBlade® system, Purity//FB would be considered a partitioned-writer system. While each blade in the system is a node containing compute power and storage capacity, the overall system contains a multitude of logical partitions, each of which has access and ownership to a specific partition of flash and NVRAM on every storage device. Virtualizing these logical partitions solves many of the scalability challenges that partitioned-writer systems have faced in the past: Instead of a partition being tied to specific hardware, FlashBlade systems allow the scaling of both performance and capacity either linearly (together) or independently. And having multiple independent logical partitions means that we can push more concurrency by allowing more parts of the system to run as fast as they can go.
Why not a shared-writer approach for scale-out?
As Ziegler et al point out, moving to a shared-writer approach without a coherent cache has the same overall scalability as a partitioned-writer model. The only disadvantage they posit for a partitioned-writer system is the difficulty scaling a cluster when adding new nodes. But with its virtualized partition model, FlashBlade’s architects solved the challenge of adding new nodes and storage to a FlashBlade cluster. Keeping these partitions also means that transactions that do not cross partitions do not require locking, which dramatically speeds up most update operations. In a shared-writer model, some locking mechanism must be implemented for every transaction, since any writer can write to any block, and this locking protocol must itself be scalable and available. And without a coherent cache, all reads, writes, and importantly metadata operations must access the underlying shared storage to determine the ground truth. Because Purity’s metadata engine is optimized for high-ingest updates, using the approach that better scales write performance was the obvious architectural choice.
And for proof of the scalability of our architecture, consider this: When the first FlashArray system launched more than 10 years ago, its max capacity was around 5 terabytes, and now with FlashArray//E™, we can deliver 4 petabytes of flash in a single array—almost a 1,000x increase. Almost as impressive, when it launched in 2017, the first FlashBlade system supported a maximum of 120TB of flash. Today, we support 30 petabytes, which is a 250-fold increase. Clearly, the scalability of our platforms has been proven in the field. And we’re not done yet, as we plan on doubling and then doubling again the size of our DirectFlash Modules in the next couple of years.
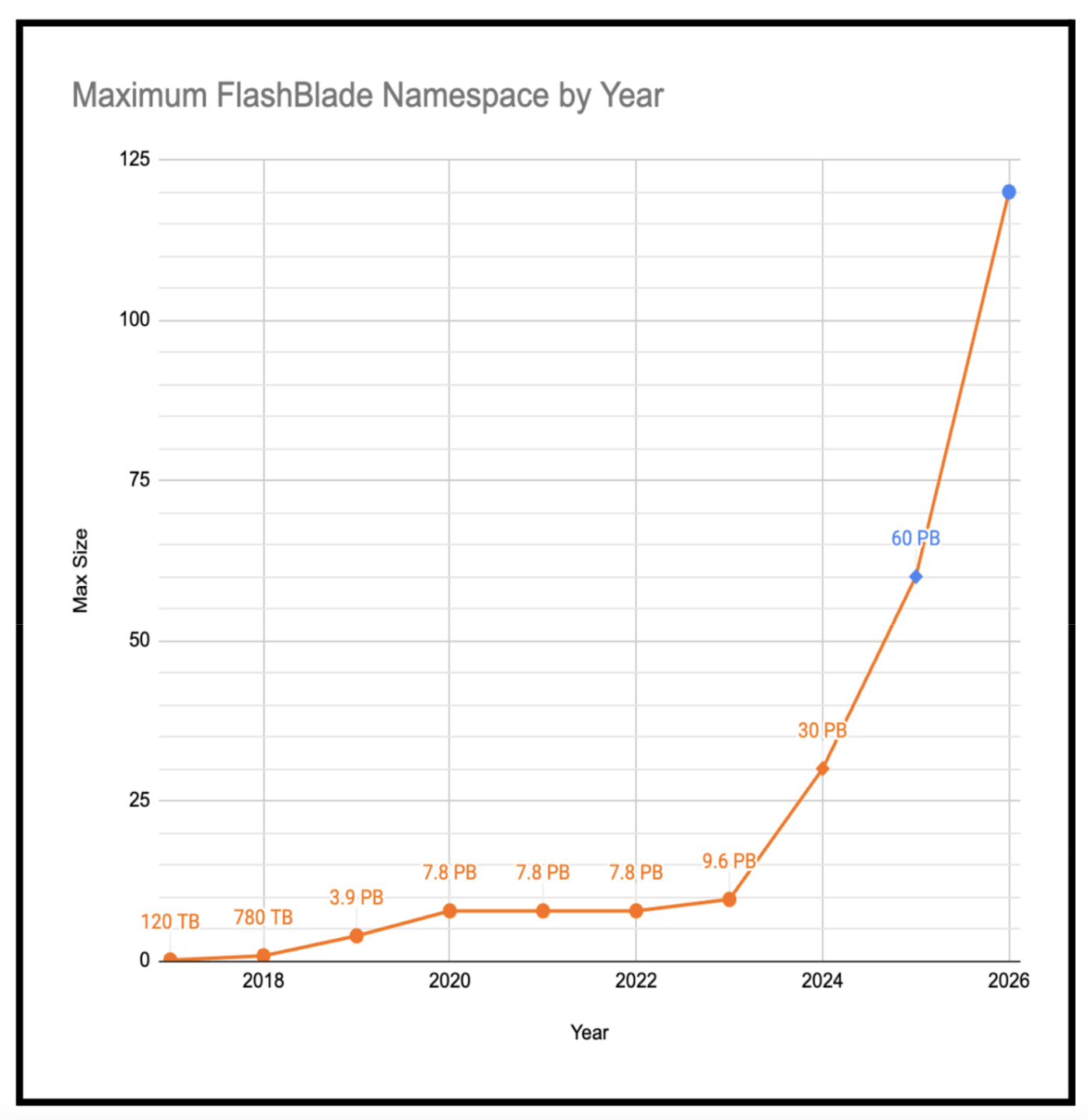
Figure 1: Evolution of the scalability of the FlashBlade architecture.
Do these categories even matter?
While much of this is interesting from an academic standpoint, the actual value that all of these systems bring is the outcomes they deliver. While we are very proud of the architecture of our systems and the scalability they deliver, we are focused on customer outcomes, and there is far more to any storage system than just its metadata architecture. A system’s reliability, customer experience, and operational simplicity are all equally if not more important than a system’s underlying architecture.
The most important aspect of a storage system is the overall capability and experience it delivers to you. When considering your organization’s storage needs, it’s important to look beyond any “marketecture” message and focus instead on what your business actually needs.
![]()



