

Image Classification — Dealing with Imbalance in Datasets
Introduction
Image classification is a standard computer vision task and involves training a model to assign a label to a given image, such as a model to classify images of different root vegetables. A big problem with classification is bias, and the models favouring a particular image class above the others. A common cause of this can be dataset imbalance, and it is often hard to spot as a model trained on an imbalanced dataset can often still have good accuracy. E.g. if there are 1000 images in the test dataset, 950 potatoes and 50 carrots and the model predicted all 1000 images to be potatoes it would still have 95% accuracy. This is also an example of why more metrics than accuracy should be considered… but let’s leave that discussion for another day.
What is imbalance?
Simply put, imbalance is an unequal distribution of classes within a dataset. It can take many forms, but is generally seen where a small number of labels are heavily over represented or under represented. The below graph shows an example of an imbalanced dataset, where carrots are under represented.

Example of an imbalanced dataset
There is no one-size-fits-all solution to imbalance, but there are a number of different techniques which each have their own merits in different situations. Four techniques will be discussed in this blog, with some examples of the different situations they might be most applicable to.
Undersampling
Undersampling is a technique based around removing images from the dataset until the distribution of classes is equalised. This technique is best used in situations where you already have a very large dataset, and the images within each class are all very similar to one another. It works very simply by selecting a subset of the images to keep, and discarding the rest! The figure below is a visualisation of what a before and after of this technique looks like for the dataset!
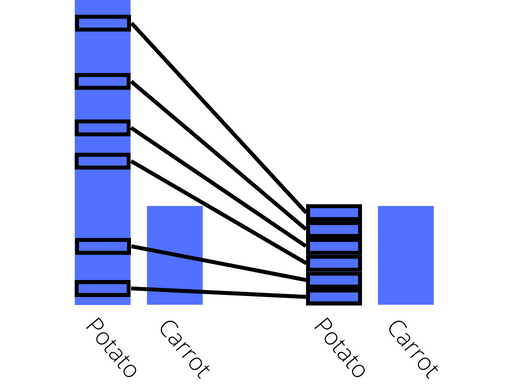
Visualisation of undersampling
There are a number of different methods that can be used to select which images to remove from the dataset, the simplest and easiest to implement is random undersampling, where the images to be kept are chosen at random. This technique is computationally very fast as it does not involve any computation or comparison of the different images. While in a lot of cases reducing the size of the dataset is not a good idea, there are still cases where it can be useful.
Oversampling
Oversampling is almost the exact opposite of undersampling, as it is a technique based around duplicating existing images to increase the size of the under represented class. This technique is best used in situations where there isn’t a huge disparity between the number of instances of each class, and the images are all reasonably similar. It works by selecting a subset of the images for a given class to duplicate. The figure below is a visualisation of what a before and after of this technique looks like for the dataset!
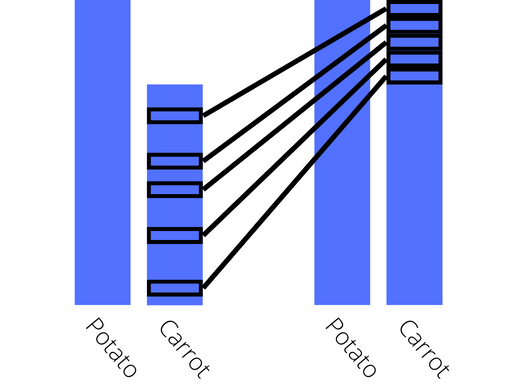
Visualisation of oversampling
Very similiarly to undersampling, there are a number of different methods that can be used to select which images to duplicate. Again the simplest and easiest to implement is random oversampling, where the images to be duplicated are chosen at random. This technique is also computationally very fast as it does not involve any manipulating of the existing images. However introducing too many duplicates to the dataset can cause issues, so other techniques, such as augmentation or generation should be considered too!
Augmentation
Augmentation is similar to oversampling, in that you increase size of an under represented class, but rather than introducing duplicates in to the data you augment (change) the images in some way. Image augmentation is a great technique that offers many benefits generally as it reduces the requirement for data gathering and also helps to generalize the training data to other unseen situations. The figure below is a visualisation of what a before and after of this technique looks like for the dataset!

Visualisation of augmentation
There are a wide variety of different augmentation techniques that can be used, but generally they fall into two categories spatial augmentation and pixel augmentation. Spatial techniques include methods such as: flipping, rotating, cropping, and scaling. Pixel techniques include changing features such as: brightness, contrast, saturation, and hue. With these techniques, and combinations of the above there is the potential to add a huge number of new images into the dataset. The figure below shows some examples of the different augmentation techniques.

Examples of different augmentation techniques
While more complex than oversampling, dataset augmentation is a more powerful technique and can be used to increase the number of instances of each class in the training dataset. Even if a class is not under represented image augmentation can still be used to increase the size of the training dataset. Fortunately, popular deep learning libraries such as TensorFlow and PyTorch have easy to implement classes to do a lot of the heavy lifting for you and make implementing augmentation fairly simple.
Synthesis
Synthesis is the process of generating new images from an existing dataset, and can be used to create new images of the under represented class to balance the dataset. This technique is best used when the dataset is already large, as to get good results a lot of input data is required. It works by utilising generative modelling, an unsupervised learning task that learns patterns in the input data to generate outputs that could pass for images from the original dataset. The figure below is a visualisation of what a before and after of this technique looks like for the dataset!
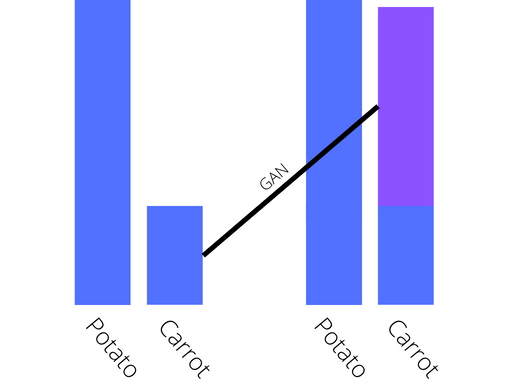
Visualisation of synthesis
Generative Adversarial Networks (GANs) are a popular deep learning approach to generative modelling and have been shown to be able to produce photorealistic images that the human eye cannot tell are fake. While considerably more complex than any of the previously discussed methods GANs have a huge amount of potential and can be used to create extremely high quality data.
Conclusion
All techniques discussed can be used to deal with dataset imbalance and each have their own pros and cons, and the best technique for each situation will eventually boil down to quality vs complexity. The use of image or augmentation or GANs will inevitably create higher quality data to address the imbalance, but the implementation can be a lot more complex and may be overkill for many situations. There is no one-size-fits-all solutions so being aware of all the techniques available allows for an informed decision to be made on the best way to tackle these sorts of problems in the future!