

Decrease Recovery Time for Microsoft SQL Server Disasters with Pure Cloud Block Store in Microsoft Azure
Pure Storage
NOVEMBER 22, 2022
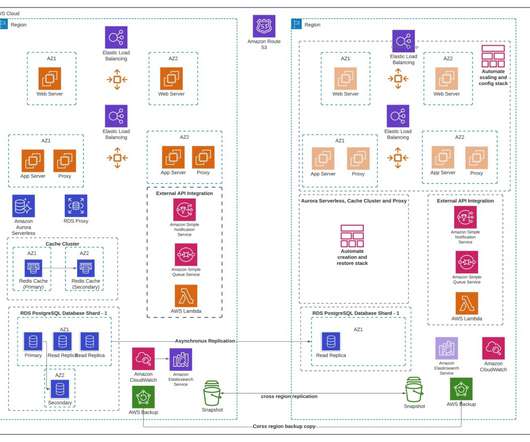
Pure Cloud Block Store is available in two versions, //V10 and //V20, in the Microsoft Azure Marketplace for Microsoft Azure deployments. The capacity listed for each model is effective capacity with a 4:1 data reduction rate. . Availability groups can be created to provide high availability, read scale, or disaster recovery. .










Let's personalize your content